- polski
-
EnglishDeutschItaliaFrançais한국의русскийSvenskaNederlandespañolPortuguêspolski繁体中文SuomiGaeilgeSlovenskáSlovenijaČeštinaMelayuMagyarországHrvatskaDanskromânescIndonesiaΕλλάδαБългарски езикGalegolietuviųMaoriRepublika e ShqipërisëالعربيةአማርኛAzərbaycanEesti VabariikEuskeraБеларусьLëtzebuergeschAyitiAfrikaansBosnaíslenskaCambodiaမြန်မာМонголулсМакедонскиmalaɡasʲພາສາລາວKurdîსაქართველოIsiXhosaفارسیisiZuluPilipinoසිංහලTürk diliTiếng ViệtहिंदीТоҷикӣاردوภาษาไทยO'zbekKongeriketবাংলা ভাষারChicheŵaSamoa日本語SesothoCрпскиKiswahiliУкраїнаनेपालीעִבְרִיתپښتوКыргыз тилиҚазақшаCatalàCorsaLatviešuHausaગુજરાતીಕನ್ನಡkannaḍaमराठी
Jak działają urządzenia IoT: architektura, komponenty i czynniki wydajności
Katalog
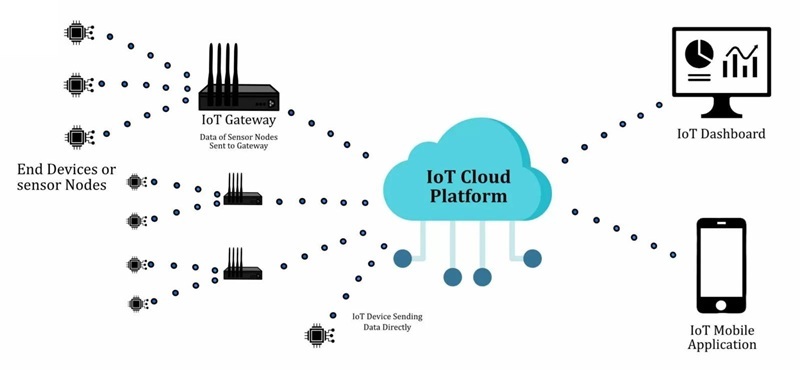
Jak działa urządzenie IoT
Produkt IoT jest łatwiejszy do zrozumienia, gdy traktuje się go jako zamkniętą, mierzalną pętlę: obserwuje świat fizyczny, przekształca to, co zaobserwowało, w dane, które elektronika może obsłużyć, przesyła te dane do miejsca, gdzie mogą zostać zinterpretowane, a następnie wyzwala reakcję. Wiele zespołów zaczyna od dążenia do „łączności”, co jest zrozumiałe, prezentacje wyglądają doskonale, gdy pulpit nawigacyjny aktualizuje się w czasie rzeczywistym, ale w terenie urządzenie ocenia się na podstawie tego, czy działa w ten sam sposób w dniu 3, dniu 30 i dniu 300.
Pętla musi przetrwać codzienne ograniczenia, które mają tendencję do pojawiania się w najgorszych momentach: ograniczona moc, nieprzewidywalna latencja, zakłócenia, limity kosztów i ewoluujące oczekiwania dotyczące bezpieczeństwa. Gdy pętla jest projektowana z uwzględnieniem tych ograniczeń, warstwy sieci i chmury wydają się być czystym rozszerzeniem produktu, a nie źródłem niespodzianek i kruchych przypadków skrajnych.
Wykrywanie: przekształcanie sygnału fizycznego w sygnał elektryczny
Na krawędzi czujnik przekształca zmienną ze świata rzeczywistego w elektryczną reprezentację, którą urządzenie może zmierzyć. Zmienna może być środowiskowa, mechaniczna lub elektryczna, a zadaniem czujnika jest stworzenie sygnału, który pozostaje interpretable pomimo wahań temperatury, wibracji i zmienności instalacji.
Zmienne ze świata rzeczywistego, najczęściej mierzone:
• Temperatura
• Wibracja
• Ciśnienie
• Światło
• Ruch
• Prąd
• Stężenie gazu
Wyjście czujnika zazwyczaj trafia do jednego z dwóch kubełków, a wybór wpływa na wszystko, co następuje później (projekt front-end, próbkowanie i tolerancja na szumy).
Typowe rodzaje wyjść czujników:
• Analogowe: ciągły wariujący napięcie lub prąd
• Cyfrowe: zpakowane odczyty przez I²C/SPI/UART
Poza warunkami laboratoryjnymi, dokładność pomiaru zależy od czegoś więcej niż tylko samego czujnika. Czynniki instalacyjne, takie jak umiejscowienie, siła montażu, przepływ powietrza, pobliskie źródła ciepła, prowadzenie kabli oraz sprzężenie mechaniczne mogą znacząco wpływać na wyniki.
Błędy pomiarowe często są spowodowane problemami z instalacją, a nie wadami czujnika. Elastyczne powierzchnie montażowe lub struktury rezonansowe mogą zniekształcać dane i tworzyć mylące odczyty. Traktowanie montażu i projektu mechanicznego jako części systemu pomiarowego pomaga zredukować czas rozwiązywania problemów i poprawia niezawodność pomiarów.
Kondycjonowanie: analogowy front-end (AFE) i higiena sygnału
Wiele urządzeń przesyła surowe wyjścia czujników przez analogowy front-end (AFE) przed cyfryzacją. Ten etap cicho kształtuje, czy reszta systemu pracuje z stabilnym, godnym zaufania sygnałem, czy z czymś, co działa tylko w kontrolowanych warunkach.
Typowe funkcje AFE:
• Biasowanie i generowanie odniesienia, aby utrzymać sygnały w ramach prawidłowego zakresu wejściowego ADC
• Wzmacnianie (wzmacniacze pomiarowe, etapy wzmocnienia), aby uczynić małe sygnały mierzalnymi
• Filtracja (filtrację dolnoprzepustową, filtrację antyaliasową), aby zmniejszyć szumy i ograniczyć mylące treści o wysokiej częstotliwości
• Ochrona (struktury ESD, ochrona przed skokami napięcia, zaciski wejściowe), aby przetrwać błędy w okablowaniu i obsłudze
Prawdziwe środowiska operacyjne często wprowadzają źródła szumów, takie jak silniki, długie kable, regulatory przełączające i pobliskie radia. Te efekty mogą powodować błędy pomiarowe, które mogą wydawać się losowe, dopóki źródło nie zostanie zidentyfikowane.
Dobre uziemienie, odpowiednie ekranowanie i podstawowa filtracja antyaliasowa często poprawiają jakość sygnału bardziej skutecznie niż poleganie wyłącznie na skomplikowanej filtracji software'owej. Rozwiązywanie problemów z szumem u źródła zazwyczaj prowadzi do bardziej wiarygodnych pomiarów i wydajności systemu.
Konwersja: Próbkowanie ADC z zamierzonymi kompromisami
Gdy sygnał jest analogowy, ADC przekształca go w cyfrowe próbki. Sama konwersja jest prosta; co wymaga doświadczenia, to dobór parametrów próbkowania, które dobrze działają w rzeczywistych ograniczeniach baterii i sieci.
Dwa wybory próbkowania, które kształtują zachowanie downstream:
• Częstotliwość próbkowania: wystarczająco szybka, aby uchwycić zjawisko, ale nie na tyle szybka, aby marnować moc i generować niepotrzebne dane
• Rozdzielczość: wystarczająco dokładna, aby wykryć znaczną zmianę bez przekształcania szumów i dryfu w fałszywą precyzję
Próbkowanie działa najlepiej, gdy jest traktowane jako decyzja na poziomie systemu, a nie jako izolowany parametr. Nadpróbkowanie może cicho wymusić więcej aktywności radiowej (a czas radiowy to często to, co pierwsze wyczerpuje baterię). Niedoprzykładowanie może pominąć krótkie, operacyjnie znaczące zdarzenia, skoki ciśnienia, uderzenia, krótkotrwałe zastoje, które użytkownicy pamiętają, ponieważ były momentem, w którym coś poszło źle.
Obliczenia: Przetwarzanie w mikroprocesorze, czasowanie i logika brzegowa
Mikroprocesor (MCU) zazwyczaj odczytuje dane z czujników według ustalonego harmonogramu, używając timerów, przerwań i DMA, aby czas urządzenia pozostawał spójny, nawet gdy oprogramowanie się rozwija. Spójne czasowanie to jeden z tych szczegółów, które wydają się nudne, dopóki pewnego dnia nie rozwiązujesz problemu w terenie i nie zdajesz sobie sprawy, że „sygnał” był tak naprawdę drganiami harmonogramu.
Typowe zadania przetwarzania po stronie MCU:
• Filtracja cyfrowa (średnia ruchoma, mediana, IIR) w celu zmniejszenia drgań i wartości odstających
• Kalibracja i kompensacja (korekcja przesunięcia, kompensacja temperatury, liniaryzacja)
• Ocena reguł (progi, histereza, debouncing), aby zapobiec niestabilnemu przełączaniu
• Lekka analiza brzegowa (wyodrębnianie cech, ocena anomalii, kompresja), aby zmniejszyć szerokość pasma i obliczenia w chmurze
Użytecznym podejściem projektowym jest oddzielenie danych pomiarowych od logiki decyzyjnej. Odczyty czujników mogą się wahać z powodu normalnych warunków fizycznych, podczas gdy stabilne zachowanie systemu można utrzymać dzięki histerezie, oknom czasowym i kontrolowaniu maszyny stanowej. To oddzielenie pomaga zmniejszyć fałszywe alarmy, poprawia stabilność systemu i zapobiega niepoprawnym wskazaniom błędu, gdy występują tymczasowe wahania pomiarowe.
Nie każda decyzja korzysta na czekaniu w chmurze. Niektóre działania są wrażliwe na czas lub zorientowane na unikanie uszkodzeń, a przekazywanie ich poza urządzenie zwykle prowadzi do niewygodnych trybów awaryjnych, gdy sieć jest powolna lub nieobecna.
Przykłady, które są często obsługiwane lokalnie:
• Zatrzymanie nadprądowe; ochrona przed przegrzaniem; wykrywanie zastoju silnika
Chmura często błyszczy, gdy zadanie korzysta z szerszego kontekstu lub dłuższych horyzontów czasowych.
Kategorie decyzji po stronie chmury:
• Analiza trendów długoterminowych i predykcyjna konserwacja
• Korelacja między urządzeniami
• Aktualizacje modelu i zmiany polityki w całej flocie
Praktyczna zasada, na którą zespoły często się zgadzają, jest prosta: jeśli opóźnione polecenie mogłoby prawdopodobnie prowadzić do uszkodzenia, urządzenie powinno najpierw się chronić i zgłaszać później. To podejście zwykle wydaje się konserwatywne w dobry sposób, zwłaszcza gdy to Ty jesteś osobą kontaktową podczas awarii sieci.
Komunikacja: Połączenia radiowe/przewodowe i protokoły aplikacji
Warstwa komunikacyjna przesyła telemetrię do telefonu, bramy lub punktu końcowego chmury. Wybór technologii łączenia dotyczy mniej tego, co jest modne, a bardziej tego, co odpowiada fizycznemu środowisku, modelowi wdrożenia i budżetowi energetycznemu.
Typowe opcje łączności:
• Wi‑Fi; BLE; Zigbee/Thread; komórkowe (LTE-M/NB-IoT); Ethernet
Powyżej warstwy łącza urządzenia używają protokołów aplikacji do strukturyzowania i dostarczania wiadomości. Odpowiedni protokół często zależy od tego, czy produkt potrzebuje telemetrii strumieniowej, workflow konfiguracji czy kompatybilności z istniejącymi rozwiązaniami w firmie.
Typowe protokoły aplikacji:
• MQTT
• HTTP
Rzeczywiste wdrożenia rzadko oferują stabilne połączenie. Punkty dostępu rebootują się, bramy znikają, zasięg komórkowy się zmienia, a zakłócenia przychodzą i odchodzą. Urządzenia wydają się znacznie bardziej niezawodne, kiedy mogą buforować dane, próbować ponownie z umiarem (nie w sposób, który DDOSuje sieć) i utrzymywać jasne zachowanie ostatniego znanego stanu, aby system pozostawał zrozumiały, gdy połączenia są niedoskonałe.
Telemetria jest zazwyczaj chroniona TLS dla poufności i integralności. W wielu produktach pierwszym zwycięstwem w zakresie bezpieczeństwa jest po prostu włączenie szyfrowania wszędzie, ale trwałe bezpieczeństwo idzie dalej, sprawiając, że tożsamość i aktualizacje są zarządzalne przez cały okres życia urządzenia.
Wspólne podstawowe elementy bezpieczeństwa:
• Unikalne tożsamości urządzeń i uwierzytelnianie oparte na certyfikatach
• Bezpieczne przechowywanie kluczy (bezpieczne elementy lub strefy zaufania MCU)
• Podpisane oprogramowanie układowe i bezpieczny rozruch, aby zmniejszyć ryzyko nieautoryzowanego wykonania kodu
Istnieje wzorzec, który doświadczone zespoły rozpoznają (często po nauce na własnych błędach): prace związane z bezpieczeństwem są znacznie mniej bolesne, gdy tożsamość, zarządzanie kluczami i ścieżki aktualizacji są zaprojektowane na wczesnym etapie. Gdy te podstawy są planowane od samego początku, urządzenie zazwyczaj pozostaje sprawne przez lata, a nie tylko do pierwszej poważnej aktualizacji w terenie.
Chmura i dane
W chmurze (lub na platformie lokalnej) dane są przechowywane, często w systemach szeregów czasowych, a następnie agregowane i analizowane. Chmura to miejsce, gdzie surowa telemetria może zostać przekształcona w wyniki, na które ktoś faktycznie będzie reagować, niezależnie od tego, czy jest to użytkownik, operator, czy zautomatyzowany silnik polityki.
Wspólne wyjścia z chmury:
• Powiadomienia (przekroczenie progów, wykrywanie awarii)
• Prognozy (pozostała użyteczna żywotność, wykrywanie dryfu)
• Pulpity nawigacyjne (WSK, trendy, zdrowie floty/urządzenia)
• Komendy kontrolne (punkty nastawy, harmonogramy, włącz/wyłącz akcje)
Wartość chmury najłatwiej uchwycić, gdy zespoły z góry decydują, jakie decyzje dane mają wspierać. Bez tej dyscypliny telemetria ma tendencję do stawania się drogim tłem, gromadzonym niezawodnie, przechowywanym sumiennie, a następnie rzadko używanym z pewnością.
Aktywowani: Wykonywanie poleceń bezpiecznie i powtarzalnie
Polecenia przesyłane z powrotem do urządzenia napędzają aktuatory, a ta część pętli to miejsce, w którym rzeczywistość sprzętowa staje się głośna. Aktywacja wymaga obwodów sterujących odpowiadających obciążeniu i korzysta z barier, które sprawiają, że awarie są przewidywalne, a nie chaotyczne.
Wspólne aktuatory:
• Silniki
• Zawory
• Przekaźniki
• Grzejniki
• Diody LED
• Głośniki
Wspólne elementy sterujące i ochronne:
• MOSFET-y; przekaźniki; mostki H; triaki (w zależności od charakterystyki obciążenia)
• Diody flyback i tłumiki (dla obciążeń indukcyjnych)
• Czujniki prądu i zabezpieczenia termiczne
• Weryfikacja stanu, gdy dostępna (przełączniki krańcowe, sprzężenie zwrotne pozycji, sygnatury elektryczne)
Mentalność niezawodności, która zazwyczaj przynosi korzyści, to założenie, że aktywacja jest miejscem, gdzie ryzyko się koncentruje. Czujniki często zawodzą cicho; aktuatory mogą ulegać awarii w sposób, który użytkownicy zauważają natychmiast. Proste zabezpieczenia, limity czasowe, blokady, kontrole sensowności często zapobiegają łańcuchowym problemom i sprawiają, że system wydaje się bardziej godny zaufania w obliczu nieuniknionych dziwnych, nieprzewidywalnych sytuacji.
Pętla się powtarza
Ten cykl: obliczenie, komunikacja, aktywacja powtarza się nieprzerwanie. Lokalne działanie może trwać milisekundy; okrążenie chmury może zająć sekundy w zależności od obciążenia sieci i zaplecza. Dobre produkty traktują czas i energię jako czynniki projektowe, które kształtują każdą inną decyzję, a nie jako coś, co można zoptymalizować na końcu.
Wspólne strategie na poziomie systemu:
• Wykorzystaj przetwarzanie brzegowe, aby zredukować niepotrzebne transmisje
• Grupuj i kompresuj telemetrię, gdy tolerancja opóźnienia na to pozwala
• Uśpij agresywnie i budź przewidywalnie w urządzeniach zasilanych bateryjnie
• Utrzymuj „minimalne zachowanie operacyjne”, nawet gdy chmura jest niedostępna
Trwałe urządzenie IoT nie jest definiowane przez żaden pojedynczy komponent. Definiuje je, jak spokojnie zachowuje się cała pętla, gdy rzeczywistość odbiega od planu: hałaśliwe sygnały, przerywane sieci, starzejący się sprzęt i nieprzewidywalne zachowanie użytkowników. Projektowanie z myślą o tych warunkach często stanowi różnicę między demonstracją, która działa raz, a produktem, który zachowuje spokój rok po roku.
Komponenty elektroniczne a wydajność urządzenia IoT
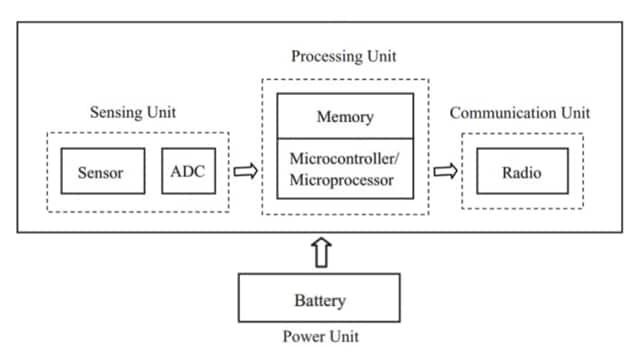
Sprzęt IoT wydaje się niezawodny tylko wtedy, gdy dane z czujników, obliczenia, przechowywanie, dostarczanie energii oraz łączność są kształtowane jako jedna ciągła ścieżka sygnału i zasilania.
Odczyt z czujnika rzadko pozostaje znaczący, jeśli napięcie odniesienia ulega zmianom, jeśli zegar jest niestabilny lub jeśli w trakcie obciążenia czasami gubione są bajty. Łączność radiowa rzadko pozostaje użyteczna, jeśli zasilanie spada podczas nadawania impulsów, jeśli oscylator jest głośny lub jeśli obsługa poświadczeń jest niespójna między resetami.
Wiele zespołów uczy się, że niezawodność często poprawia się bardziej przez zaostrzenie granic między blokami niż przez dodawanie kolejnej funkcji: przewidywalne szyny, ograniczony czas, kontrolowane sprzężenie szumów i zachowanie w przypadku awarii, które jest zrozumiałe, gdy coś się psuje.
Celem projektowania nie są „idealne części”, ale interfejsy, które działają w ten sam sposób na stanowisku dewelopera, w pilotażowych wdrożeniach i miesiące później w terenie.
Czujnik
Czujniki przekształcają warunki ze świata rzeczywistego w sygnały elektryczne, ale codzienne zachowanie produktów kształtowane jest przez szczegóły, które mogą wydawać się małe, dopóki dane z terenu nie sprawią, że będą niepokojąco duże.
Szumy, dryf, montaż, przepływ powietrza, kondensacja i prowadzenie kabli mają tendencję do przekształcania czystych wykresów laboratoryjnych w chaotyczne rozkłady, które oprogramowanie musi przetrwać.
Zasięg i rozdzielczość muszą odpowiadać podejmowanej decyzji, a nie specyfikacji nagłówkowej. Zbyt wrażliwe konfiguracje często wzmacniają szumy i dryf, co zazwyczaj prowadzi do fałszywych pozytywów i cichutko zwiększa czas obliczeń i czas transmisji radiowej. Najwęższy możliwy zasięg może wyglądać na uzasadniony podczas przeglądów projektowych, jednak zachowanie w terenie często favoruje nieco szerszy zasięg, który produkuje stabilniejsze, bardziej interpretowalne pomiary. Jeśli model lub próg downstream ma w każdym razie wygładzać dane, przeprowadzanie surowej wrażliwości zbyt daleko może na początku wydawać się zadowalające, a potem frustrujące, gdy zaczynają napływać zgłoszenia.
Dryf, starzenie się i ekspozycja decydują o tym, czy pomiary pozostają wiarygodne po miesiącach lub latach.
Kalibracja zazwyczaj działa lepiej, gdy traktowana jest jako rutyna cyklu życia, a nie pojedynczy rytuał fabryczny, który wszyscy mają nadzieję, że będzie trwał wiecznie.
• Kalibracja fabryczna z przechowywanymi współczynnikami.
• Wyzwalacze ponownej kalibracji w terenie (zaplanowane, oparte na wydarzeniach lub wspierane przez technika).
• Rutyny samosprawdzania, które oznaczają wartości odstające, przycinanie i nasycenie.
Zespoły dążące do tworzenia produktów nadających się do serwisowania często odkładają umiarkowaną ilość pamięci flash i obliczeń na metadane kalibracyjne, śledzenie i kontrole sanity, ponieważ jest to tańsze niż wyjaśnianie niespójnych odczytów po wdrożeniu.
Wybór częstotliwości próbkowania zazwyczaj przekształca się w negocjację między fizyką, akumulatorami a użytecznością danych. Zbyt wolne próbkowanie grozi aliasingiem i utraconymi zdarzeniami, co może być trudne do zdiagnozowania, ponieważ dane nadal wyglądają na wiarygodne. Zbyt szybkie próbkowanie zwiększa pobór mocy i objętość danych, co może stworzyć iluzję lepszego wglądu bez materialnego poprawienia decyzji.
Wzór, który dobrze się sprawdza, to uchwycenie zjawiska z wystarczającą marginesem, wczesne filtrowanie (analogowe, gdy naprawdę pomaga, cyfrowe, gdy jest wystarczające) i próbkowanie w dół do raportowania.
To często przynosi lepsze wyniki baterii niż agresywne próbkowanie i nadzieja, że analityka chmurowa skompensuje to później.
To, czy zewnętrzny ADC jest uzasadniony, zwykle zależy od rozdzielczości, impedancji wejściowej, stabilności odniesienia i tolerancji na szum. Zintegrowane ADC w MCU często dobrze sprawdzają się w przypadku zadań o średniej rozdzielczości, podczas gdy sygnały o wysokiej precyzji mają tendencję do karać luźny układ i wybory odniesienia.
• Wybór niskoszumowego odniesienia i prowadzenie odniesienia.
• Strategia uziemienia, ślady ochronne i kontrola ścieżek powrotu.
• Osłona i zamierzona trasa kablowa w pobliżu złączy.
• Ochrona ESD umieszczona tam, gdzie rzeczywiście przechwytuje transient.
Małe zmiany na PCB mogą znacząco zmniejszyć jitter i poprawić powtarzalność, zwłaszcza dla źródeł o wysokiej impedancji lub niskiego sygnału analogowego, gdzie „prawie w porządku” staje się widocznie niestabilne w danych produkcyjnych.
Mikrokontroler (MCU)
MCU działa jako centrum operacyjne: odczytuje czujniki za pośrednictwem GPIO, I²C, SPI i UART; przetwarza sygnały; przeprowadza wnioskowanie tam, gdzie to możliwe; zarządza trybami zasilania; i steruje wyjściami.
Kiedy zachowanie MCU jest przewidywalne, całe urządzenie wydaje się spokojne; gdy tak nie jest, awarie mają tendencję do bycia losowymi nawet wtedy, gdy przyczyna jest deterministyczna.
Stabilne oprogramowanie układowe zazwyczaj pochodzi od wyraźnych maszyn stanowych i timingów, które mają jasne granice. Projekty oparte na zdarzeniach wykorzystujące przerwania, DMA i timery zwykle przewyższają pętle pollingowe pod względem reaktywności i energii, szczególnie w urządzeniach, które często usypiają.
Gdy zespoły opisują losowe zawieszenia, winowajcą często jest jeden z kilku powtarzających się sprawców: nieograniczone prace wewnątrz przerwania, zakleszczenie na wspólnej magistrali, inwersja priorytetów lub fragmentacja pamięci, która nigdy nie była testowana pod kątem obciążeń długoterminowych.
Planowanie pamięci RAM i flash działa lepiej, gdy obejmuje to, co się dzieje po pierwszej udanej demonstracji.
• Bufory sieciowe i koszty TLS (w tym zachowanie handshake w najgorszym przypadku).
• Logi, metry i zrzuty awarii, o które inżynierowie będą prosić później.
• Miejsce stagingowe OTA, plus metadane do sprawdzania integralności.
• Zjawisko "feature creep", które przewidywalnie pojawia się po feedbacku z pilotażu.
Zbyt mała pamięć często pozostaje cicha na początku, a później staje się bolesna, w momencie, gdy diagnostyka i bezpieczeństwo aktualizacji stają się głównymi narzędziami do kontrolowania ryzyka w terenie.
Urządzenia, od których oczekuje się zaufania, zazwyczaj korzystają z zabezpieczonego bootowania, chronionego przechowywania kluczy, sprzętowego przyspieszania kryptografii oraz prawdziwego generatora liczb losowych. Z doświadczenia wdrożeniowego, poprawki bezpieczeństwa często stają się niewygodne, ponieważ kolidują z ograniczeniami sprzętowymi i długożyjącymi poświadczeniami.
Wybór MCU (lub dodanie bezpiecznego elementu), który obsługuje silną tożsamość i mierzone bootowanie, często redukuje ilość sprytnego oprogramowania potrzebnego do rekompensacji słabych fundamentów zaufania.
Dostęp do SWD/JTAG i praktyczna testowalność zazwyczaj decydują o tym, czy wczesna produkcja jest kontrolowana, czy chaotyczna.
• Planowanie dostępu SWD/JTAG oraz strategia blokady dla produkcji.
• Podkłady testowe i przyjazny układ dla wysokowolumenowych uchwytów.
• Punkty czujników szyn zasilania i mierzalne węzły do szybkiej diagnozy.
Niewielka ilość infrastruktury testowej może zaoszczędzić zespołom tygodnie niewygodnego zgadywania, gdy pierwsza duża partia ujawnia przypadki brzegowe, które nigdy nie pojawiły się na zbudowanych ręcznie prototypach.
Moduły komunikacyjne
Moduł komunikacyjny kształtuje więcej niż budżet łącza: wpływa na przydzielanie zasobów, zachowanie aktualizacji, przepływy wsparcia i zaskakującą liczbę trybów awarii.
W urządzeniach zasilanych bateriami, zachowanie radia często dominuje nad zużyciem energii, więc decyzje dotyczące łączności stają się decyzjami dotyczącymi żywotności baterii w przebraniu.
Wybór zwykle bilansuje zasięg, opóźnienie, przepustowość, topologię i budżet mocy, z frankowym spojrzeniem na tarcia operacyjne.
• BLE do krótkiego zasięgu, niskiego zużycia energii oraz uruchamiania za pomocą smartfona.
• Wi‑Fi dla wyższej przepustowości z wyższym szczytowym prądem i surowszymi wymaganiami na integralność energetyczną.
• Thread/Zigbee dla sieci mesh i niskonapięciowych wdrożeń domowych/przemysłowych.
• LoRaWAN dla długiego zasięgu, niskich prędkości transmisji i ścisłej dyscypliny ładunku.
• LTE‑M/NB‑IoT dla szerokozasięgowej pokrywy z ograniczeniami operatora i bardziej skomplikowanym przydzielaniem zasobów.
Zespoły często odczuwają ulgę, gdy przyznają, że „wybór radia” jest nierozłącznie związany ze strategią ponownego wysyłania oprogramowania, obsługą szczytowego prądu i cierpliwością użytkownika podczas konfiguracji.
Silny moduł może nadal zawieść, jeśli antena jest źle umiejscowiona, zestrojona przez obudowę lub narażona na hałaśliwy powrót ziemski.
• Strefy wykluczenia anteny i kontrolowane okablowanie impedancyjne.
• Efekty obudowy i testowanie interakcji użytkownika.
• Kontrole promieniowanych emisji i próby podatności.
Gdy margines łącza jest cienki, ponowne próby oprogramowania mogą maskować objaw przez pewien czas, ale koszt energii akumuluje się w sposób, który zespoły operacyjne zauważają znacznie przed tym, jak inżynierowie zobaczą to w laboratorium.
Projekt łączności musi przetrwać rzeczywiste przepływy pracy, a nie idealne demonstracje.
• Przydzielanie zasobów, które toleruje częściowe awarie i powszechne błędy użytkowników.
• Logika wycofania i ponownej próby, która unika samodzielnie wywołanych spiral wyczerpania baterii.
• Zachowanie roamingowe oraz zarządzanie cyklem życia SIM/eSIM dla urządzeń komórkowych.
• OTA z uwierzytelnianiem, możliwością przywrócenia i harmonogramowaniem z uwzględnieniem przepustowości.
Funkcje OTA działają mniej jak błyszcząca funkcja, a bardziej jak długoterminowy kanał konserwacyjny; gdy jest traktowane powierzchownie, urządzenia stają się kosztowne w obsłudze, nawet jeśli pierwsze wdrożenie wygląda dobrze.
Zarządzanie zasilaniem
Projekt zasilania utrzymuje urządzenie przy życiu, powtarzalne i nudne, w najlepszym znaczeniu tego słowa. Obejmuje to regulatory, ładowanie, pomiar paliwa, przełączanie obciążenia i wybór ochrony, które muszą radzić sobie zarówno z wydarzeniami szczytowego prądu, jak i oczekiwaniami głębokiego snu.
Wybór Buck/boost/LDO korzysta z oceny efektywności w pełnym zakresie obciążenia, a nie tylko w jednym punkcie roboczym. Prąd spoczynkowy w trybie uśpienia często decyduje, czy produkt spełnia oczekiwania dotyczące baterii.
Radia mogą tworzyć ostre szczyty prądu; pojemności objętościowe, niskoodporowe okablowanie i stabilne pętle kontrolne zazwyczaj decydują, czy system pozostaje aktywny podczas wybuchów transmisji. Wiele tajemniczych resetów okazuje się wynikać z przejściowych spadków, a nie z oprogramowania, co może być pokorną, ale użyteczną lekcją podczas integracji.
Żywotność baterii zazwyczaj wygrywa się podczas snu, gdzie małe wycieki kumulują się w mierzone straty.
• Konfiguracja głębokiego snu tylko z źródłami wybudzenia, które są faktycznie używane.
• RTC lub niskoprądowe timery do okresowych wybudzeń.
• Przerwania GPIO lub czujników do wybudzeń wywołanych zdarzeniami.
• Gromadzenie mocy dla czujników i peryferiów, które nie wymagają ciągłego zasilania.
Pomiar snu we wczesnym stadium na rzeczywistym sprzęcie, a następnie traktowanie niespodziewanych wzrostów mikroamperów jako błędów, zwykle zapobiega powolnemu osłabieniu, gdzie wiele bloków „prawie wyłączonych” cicho eroduje czas działania.
Wybór układu scalonego do ładowania zależy od chemii, ograniczeń termicznych, wymogów regulacyjnych i spodziewanego środowiska. Wybór wskaźnika paliwa powinien odzwierciedlać potrzeby dokładności w różnych temperaturach, obciążeniach i starzeniu się. W przypadku wdrożeń na zewnątrz lub w nieogrzewanych miejscach, zachowanie w niskich temperaturach często staje się kluczowym czynnikiem postrzeganej jakości, dlatego konserwatywne progi napięcia i uczciwe raportowanie pojemności zmniejszają skargi na nagłe wyłączenia.
Zjawiska przeciążenia, nadnapięcia, odwrotnej polaryzacji oraz zachowanie ESD powinny być traktowane jako rutynowe warunki pracy w wielu wdrożeniach. Środowiska przemysłowe zwykle generują zdarzenia wyładowań kabli i przejściowe zjawiska indukcyjne, które mogą wyglądać jak „złe szczęście”, chyba że projekt je przewiduje. Odpowiednie zaciski, bezpieczniki, diody TVS, kontrola prądów rozruchowych oraz decyzje o izolacji często decydują o tym, czy urządzenie przetrwa swój pierwszy miesiąc z nienaruszoną reputacją.
Komponenty pamięci
Pamięć przechowuje oprogramowanie, konfigurację, certyfikaty i dzienniki. Wybór między pamięcią NOR/NAND, EEPROM, FRAM, eMMC lub microSD zwykle napotykany jest przez trwałość, wydajność, koszty materiałów oraz to, jak bolesne byłoby operacyjnie uszkodzone zapisanie.
Rzeczywiste urządzenia stają w obliczu brązowych wyładowań, resetów watchdogów i częściowych zapisów.
• Sumy kontrolne lub CRC dla konfiguracji i dzienników.
• Poziomowanie zużycia lub ograniczona częstotliwość zapisu dla mediów opartych na pamięci flash.
• Dziennikowanie lub tylko dołączanie rekordów dla danych, które nie mogą być zapisane częściowo.
Częstym wzorcem operacyjnym jest logowanie w buforze cyklicznym z ograniczonymi wskaźnikami zapisu, co ogranicza ciche zużycie trwałości, pozostawiając jednocześnie wystarczającą ilość „okruszków” do debugowania problemów w terenie.
Sloty oprogramowania A/B oraz zweryfikowane uruchamianie i logika wycofania zapewniają praktyczną siatkę bezpieczeństwa podczas przerwanych aktualizacji. Bez tych zabezpieczeń, pojedyncza utrata zasilania podczas aktualizacji może unieruchomić urządzenia w terenie. Produkty, które płynnie się skalują, zwykle traktują zdolność do odzyskiwania na równi z funkcjami dostarczanymi, ponieważ koszty wsparcia zwykle korelują z jakością historii odzyskiwania.
Certyfikaty i klucze powinny być przechowywane z myślą o odporności na manipulacje i kontroli dostępu, a nie tylko w jakimś miejscu nieulotnym. Nawet przy bezpiecznym przechowywaniu, plany rotacji kluczy, unieważnienia i reakcji na incydenty zmniejszają długotrwałe narażenie, gdy dane uwierzytelniające wyciekają lub flota jest częściowo skompromitowana.
Komponenty interfejsu
Diody LED, wyświetlacze, przyciski, mikrofony, kamery i czujniki biometryczne kształtują użyteczność, ale także pociągają za sobą zużycie energii, ryzyko EMI oraz aspekty prywatności. Interfejs użytkownika, który wydaje się spójny w sytuacjach stresowych, często odzwierciedla bardziej zdyscyplinowany projekt elektryczny niż polerowanie interfejsu.
Przyciski zazwyczaj wymagają eliminacji drgań i ochrony ESD, aby uniknąć sporadycznych błędów odczytu.
Mikrofony i kamery zwykle potrzebują czystych zasilaczy i starannego uziemienia, aby uniknąć przerywanych artefaktów, które użytkownicy interpretują jako „niestabilne”.
• Oddzielenie wrażliwych ścieżek analogowych od wysokoprądowych przełączników i ścieżek RF.
• Planowanie ścieżek powrotnych, aby ograniczyć sprzężenie szumów.
• Wybory ekranowania i filtracji dostosowane do strategii obudowy i kabli.
Przerywane awarie interfejsu użytkownika są często spowodowane sprzężeniem z radiami lub silnikami, a ich naprawa poprzez dyscyplinę układu i uziemienia może być zaskakująco satysfakcjonująca, zamiast niekończących się obejść oprogramowania układowego.
Urządzenia zachowują się bardziej przewidywalnie, gdy mają offline’ową historię, która nie polega na dostępności sieci.
Wyraźna lokalna informacja zwrotna (jednoznaczne stany diod LED i minimalne, dokładne sygnały błędów) zmniejsza obciążenie wsparcia i unika frustracji użytkowników, która wynika z cichego zachowania awaryjnego.
Aktuatory
Aktuatory przekształcają zamiar sterowania w ruch, ciepło lub siłę, i zazwyczaj wymagają układów interfejsowych wykraczających poza bezpośredni pin MCU. Ponieważ aktuatory oddziałują ze światem fizycznym, tryby awarii zwykle są widoczne, kosztowne i powodują emocjonalne reakcje użytkowników. Silniki, cewki, zawory i przekaźniki zazwyczaj potrzebują stopni MOSFET, mostków H lub dedykowanych układów scalonych z napędem dobranych do rzeczywistych prądów i przejść.
• Diody flyback lub tłumiki dla obciążeń indukcyjnych.
• Optyka prądowa do wykrywania zastoju i reakcji na przeciążenia.
• Rozważania dotyczące konstrukcji termicznej dla obciążeń ciągłych lub o wysokim cyklu pracy.
Doświadczenie w terenie często pokazuje, że problemy związane z aktuatorami są częstym źródłem awarii, a konserwatywne obniżenie oraz wykrywanie usterek zwykle poprawiają zachowanie floty w sposób szybko dostrzegany przez zespoły wsparcia.
Urządzenie powinno pozostać bezpieczne, gdy oprogramowanie się zawiesza, chmura jest niedostępna lub polecenia przychodzą późno.
• Watchdogi i strategia resetu zgodne z bezpiecznymi wyjściami.
• Zdefiniowane domyślnie bezpieczne stany wyjścia per aktuator i per tryb.
• Mechaniczne pozycje awaryjne, gdzie tego wymaga aplikacja.
Najbardziej odporne projekty traktują utratę łączności jako normalny tryb pracy i dokładnie definiują, co napędzacz robi w tym okresie, więc zachowanie pozostaje przewidywalne, nawet gdy wszystko inne jest niedoskonałe.
Integracja na poziomie systemu
Wysokiej jakości poprawki często pochodzą z praktyk integracyjnych, które zmuszają cały system do wczesnego mówienia prawdy.
• Walidacja integralności zasilania w najgorszym przypadku obciążenia radiowego i napędzacza.
• Kontrola hałasu w czujnikach analogowych, regulatorach przełączających i driverach o dużym prądzie.
• Procesy rozruchu, aktualizacji i odzyskiwania z mierzalnymi stanami i wyraźną obserwowalnością.
• Testowanie środowiskowe (temperatura, wilgotność, wibracje) dobrane do faktycznych warunków wdrożenia.
Kiedy te działania są traktowane jako codzienna praca inżynieryjna, a nie ceremonia na końcu etapu, wybory komponentów zwykle stają się mniej dramatyczne, a zachowanie urządzenia pozostaje spójne od prototypu do masowego wdrożenia.
Wnioski
Udane systemy IoT opierają się na pełnej i niezawodnej pętli danych, która obejmuje sensing, kondycjonowanie sygnału, przetwarzanie, komunikację, bezpieczeństwo i zarządzanie zasilaniem. Każdy etap wpływa na ogólną wydajność, żywotność baterii, dokładność i doświadczenia użytkownika. Poprzez zrównoważenie sprzętu, oprogramowania, sieci i ograniczeń operacyjnych, urządzenia IoT mogą dostarczać niezawodne monitorowanie, kontrolę i automatyzację w szerokim zakresie zastosowań.
Najczęściej zadawane pytania [FAQ]
1. Dlaczego wiele projektów IoT nie udaje się z powodu jakości pomiarów, a nie problemów z łącznością?
Łączność często przyciąga najwięcej uwagi podczas rozwoju, ponieważ pulpity nawigacyjne i integracje w chmurze są bardzo widoczne. Niemniej jednak, niedokładne pomiary spowodowane złym umiejscowieniem czujników, wibracją, efektami przepływu powietrza, sprzężeniem cieplnym, hałasem lub błędami instalacyjnymi mogą podważyć cały system. Jeśli dane oryginalne są niewiarygodne, nawet najbardziej zaawansowane analizy, platformy chmurowe i sieci komunikacyjne nie mogą podejmować wiarygodnych decyzji. Długoterminowy sukces IoT zazwyczaj zaczyna się od stabilnych pomiarów, a nie od zaawansowanych funkcji łączności.
2. Dlaczego montaż czujników powinien być traktowany jako część samego systemu pomiarowego?
Czujniki mierzą warunki fizyczne przez interakcję z otaczającym środowiskiem. Siła montażowa, projekt obudowy, prowadzenie kabli, przepływ powietrza, transfer wibracji i kontakt cieplny mogą zmienić to, co czujnik postrzega. Idealnie skalibrowany czujnik może nadal generować mylące odczyty, jeśli jest źle zamontowany. W wielu wdrożeniach błędy związane z instalacją przyczyniają się do większej niepewności pomiaru niż same specyfikacje czujnika, co sprawia, że integracja mechaniczna jest krytycznym elementem ogólnej wydajności pomiarowej.
3. Dlaczego nadpróbkowanie jest często ukrytym zagrożeniem dla żywotności baterii w urządzeniach IoT?
Próbkowanie danych częściej niż to konieczne zwiększa obciążenie przetwarzania, zużycie pamięci i aktywność komunikacyjną. Ponieważ transmisja bezprzewodowa jest często największym konsumentem energii w zasilanych bateriami produktach IoT, zbieranie nadmiaru danych może pośrednio zwiększyć zużycie energii przez radio i skrócić czas pracy. Choć wysokie częstotliwości próbkowania mogą wydawać się poprawiać dokładność, często tworzą większe zestawy danych bez dostarczania znaczących ulepszeń w jakości decyzji. Skuteczne strategie próbkowania równoważą wymagania dotyczące detekcji zdarzeń z zużyciem energii i potrzebami w zakresie raportowania.
4. Dlaczego udane urządzenia IoT oddzielają logikę pomiaru od logiki podejmowania decyzji?
Surowe wartości czujników naturalnie fluktuują z powodu hałasu, zmienności środowiska i normalnego zachowania procesów. Jeśli każdy pomiar bezpośrednio wywołuje działanie, systemy mogą stać się niestabilne i generować fałszywe alarmy. Oddzielając zbieranie pomiarów od logiki decyzji z użyciem histerezy, maszyn stanów, filtracji, okien czasowych i reguł walidacji, urządzenia mogą pozostawać responsywne, unikając niepotrzebnych reakcji na chwilowe fluktuacje. Takie podejście poprawia niezawodność i sprawia, że zachowanie systemu jest bardziej przewidywalne w warunkach rzeczywistych.
5. Dlaczego wiele krytycznych decyzji IoT jest przetwarzanych lokalnie zamiast delegowanych do chmury?
Systemy chmurowe dostarczają cennych analiz długoterminowych, zarządzania flotą i predykcyjnych spostrzeżeń, ale opóźnienia w sieci i awarie mogą sprawić, że będą one nieodpowiednie dla funkcji ochrony wrażliwych na czas. Zdarzenia takie jak warunki nadprądowe, przegrzewanie, zastoje silników czy wyłączenia awaryjne często wymagają natychmiastowej reakcji. Czekanie na potwierdzenie z chmury może pozwolić na uszkodzenie sprzętu lub rozwój niebezpiecznych warunków. Z tego powodu krytyczne decyzje dotyczące ochrony i kontroli są często podejmowane na brzegach, podczas gdy platformy chmurowe koncentrują się na monitorowaniu i optymalizacji.
Powiązany blog
-
Ile zer na milion, miliard, bilion?
![Ile zer na milion, miliard, bilion?]()
2024/07/29
Million reprezentuje 106, łatwo chwytana liczba w porównaniu do przedmiotów codziennych lub rocznych pensji. Miliard, równoważny 109, zaczyna roz... -
IRLZ44N MOSFET Arkusz, obwód, równoważny, pinout
![IRLZ44N MOSFET Arkusz, obwód, równoważny, pinout]()
2024/08/28
IRLZ44N to szeroko stosowany Mosfet Power N-Kannel.Znany z doskonałych możliwości przełączania, jest bardzo odpowiedni do wielu zastosowań, szcz... -
Temperatura akumulatora zbyt niska, ładowanie zatrzymało się.Jak to naprawić?
![Temperatura akumulatora zbyt niska, ładowanie zatrzymało się.Jak to naprawić?]()
2024/10/6
Problemy z ładowaniem baterii telefonu komórkowego są powszechne, ale można je skutecznie zarządzać.Temperatura odgrywa dużą rolę w wydajnoś... -
BC547 Tranzystor Kompleksowy przewodnik
![BC547 Tranzystor Kompleksowy przewodnik]()
2024/07/4
Tranzystor BC547 jest powszechnie stosowany w różnych zastosowaniach elektronicznych, od podstawowych wzmacniaczy sygnałowych po złożone obwody o... -
Kompleksowy przewodnik po SCR (prostownik kontrolowany krzem)
![Kompleksowy przewodnik po SCR (prostownik kontrolowany krzem)]()
2024/04/22
Kontroli prostownicy (SCR) lub Thyristors odgrywają kluczową rolę w technologii elektroniki energetycznej ze względu na ich wydajność i niezawod... -
LR621, SR621SW, 364, AG1 Equivivalents i zamienniki
![LR621, SR621SW, 364, AG1 Equivivalents i zamienniki]()
2024/07/15
Baterie przycisków LR621 i SR621SW są powszechne w kompaktowych urządzeniach elektronicznych, takich jak zegarki, małe zabawki, kalkulatory i zdal... -
Kompletny przewodnik po multiplekserach i ich rola w systemach cyfrowych
![Kompletny przewodnik po multiplekserach i ich rola w systemach cyfrowych]()
2025/09/20
Multipleksery są komponentami w systemach cyfrowych, zaprojektowanych do kierowania wieloma sygnałami wejściowymi do pojedynczej linii wyjściowej ... -
Podstawy obwodów OP-AMP
![Podstawy obwodów OP-AMP]()
2023/12/28
W skomplikowanym świecie elektroniki podróż do jej tajemnic niezmiennie prowadzi nas do kalejdoskopu komponentów obwodów, zarówno wykwintnych, j... -
Porównanie różnic i zastosowań NMOS i PMOS
![Porównanie różnic i zastosowań NMOS i PMOS]()
2024/11/15
Zrozumienie różnic między tranzystorami NMOS i PMO jest ważne w projektowaniu wydajnych obwodów.NMOS (NMOS-semiconductor) i PMOS (typ p-tlenku-tl... -
CR2450 vs CR2032 Porównanie: Wszystko, co musisz wiedzieć
![CR2450 vs CR2032 Porównanie: Wszystko, co musisz wiedzieć]()
2025/09/15
Baterie guzików, takie jak CR2450 i CR2032, zasilają wiele codziennych elektroniki, od zegarków i pilotów po urządzenia medyczne i przemysłowe.C...










Gorące części
- AD797ARZ-REEL7
- HA17008RFP-EL
- STM32F733IEK6
- TPSD337K004R0045
- CSPU877ABVG8
- TSI310A-133CEY
- S1M
- DFLS130LQ-7
- MTCH6301-I/ML
- GRM1555C1H9R0CA01J
- SN75ALS170DWRG4
- M29W128GH-70N6
- MAX7219EWG+T
- AR2317-AC1A
- QMK212B7682MGHT
- 2MBI100S-120
- CXD5143GG-T2
- MT5382AR/A-ATSL
- IPL65R190E6
- PIC16F1704-I/SL
- SC441071CFNR2
- AS4C256M16D3LA-12BCN
- MLX90316LGO-BCG-000-RE
- PCF8579T/1
- SN74LS32NS
- CY2220PVC-1
- MBRD835LT4G
- ADS7864YB
- ACPM-5501-TR1
- ADS8344E
- 1808CA100JAT1A
- CXA3572R
- TAJT155K025RNJ
- T491C476K016AT4539
- VI-J73-IZ
- 74LV139PW+118
- BC57E687CAU
- CP2543-A11-GMR
- CSPU877BVD
- MT47H64M16HR-3IT:G
- 6MBP75RA-060
- EE80C196KB-16
- K9F1G08U0E-SCB0000
- K9W8G08U1M-PIB
- OZ77C6LN
- SC668021MLH
- MN103SE4KPR
- BQ79656PAPRQ1
- MP5416GR-0001-Z
- PD69200R-034600