- polski
-
EnglishDeutschItaliaFrançais한국의русскийSvenskaNederlandespañolPortuguêspolski繁体中文SuomiGaeilgeSlovenskáSlovenijaČeštinaMelayuMagyarországHrvatskaDanskromânescIndonesiaΕλλάδαБългарски езикGalegolietuviųMaoriRepublika e ShqipërisëالعربيةአማርኛAzərbaycanEesti VabariikEuskeraБеларусьLëtzebuergeschAyitiAfrikaansBosnaíslenskaCambodiaမြန်မာМонголулсМакедонскиmalaɡasʲພາສາລາວKurdîსაქართველოIsiXhosaفارسیisiZuluPilipinoසිංහලTürk diliTiếng ViệtहिंदीТоҷикӣاردوภาษาไทยO'zbekKongeriketবাংলা ভাষারChicheŵaSamoa日本語SesothoCрпскиKiswahiliУкраїнаनेपालीעִבְרִיתپښتوКыргыз тилиҚазақшаCatalàCorsaLatviešuHausaગુજરાતીಕನ್ನಡkannaḍaमराठी
Co to jest NPU i jak działa w urządzeniach AI?
Katalog

Co to jest NPU?
Jednostka przetwarzania neuronowego (NPU) to procesor zaprojektowany specjalnie z myślą o obciążeniach związanych ze sztuczną inteligencją i sieciami neuronowymi.W przeciwieństwie do procesora, który obsługuje wiele różnych typów zadań obliczeniowych, jednostka NPU koncentruje się głównie na operacjach wykorzystywanych w głębokim uczeniu się, rozpoznawaniu obrazów, przetwarzaniu mowy, wykrywaniu wzorców i wnioskowaniu AI.Ponieważ sprzęt jest zoptymalizowany pod kątem tych obciążeń, może przetwarzać zadania AI znacznie szybciej, zużywając znacznie mniej energii.
Tradycyjne procesory, takie jak CPU i GPU, nadal mogą obsługiwać modele AI, ale nie są w pełni zoptymalizowane pod kątem obliczeń w sieci neuronowej.Podczas intensywnego przetwarzania sztucznej inteligencji często zużywają więcej energii elektrycznej, wytwarzają więcej ciepła i wydają dodatkowe zasoby na operacje niezwiązane ze sztuczną inteligencją.W miarę ciągłego rozszerzania się funkcji sztucznej inteligencji w smartfonach, urządzeniach IoT, kamerach, pojazdach, robotyce i systemach brzegowych ograniczenia te stają się coraz bardziej zauważalne w rzeczywistych zastosowaniach.
Jednostka NPU usprawnia wykonywanie sztucznej inteligencji, organizując swój sprzęt wokół rzeczywistego przepływu obliczeń sieci neuronowej.Zamiast czekać w długich kolejkach instrukcji, przez procesor przepływają jednocześnie duże ilości danych.Sprzęt w sposób ciągły wykonuje operacje, takie jak mnożenie macierzy, splot, obliczenia tensorowe i równoległe przetwarzanie danych, które stanowią podstawę nowoczesnych modeli sztucznej inteligencji.Ograniczając niepotrzebną obsługę instrukcji i skracając ścieżki przepływu danych, procesor efektywniej realizuje zadania AI.
Jedną z głównych różnic między jednostką NPU a procesorem jest sposób przetwarzania operacji.Procesor zwykle wykonuje instrukcje krok po kroku, stale przełączając się między wieloma zadaniami systemowymi.Jednostka NPU działa inaczej, dzieląc obciążenia AI na wiele mniejszych operacji, które działają jednocześnie na wielu jednostkach obliczeniowych.Ta równoległa struktura jest bardzo skuteczna w przypadku takich zadań, jak analiza obrazu w czasie rzeczywistym, rozpoznawanie głosu, ulepszanie wideo, wykrywanie twarzy i przetwarzanie języka, gdzie jednocześnie muszą być przetwarzane bardzo duże ilości danych.
Nowoczesne jednostki NPU poprawiają również wydajność dzięki uproszczonym rdzeniom przetwarzającym, zoptymalizowanym strukturom pamięci podręcznej i zestawom instrukcji zaprojektowanym specjalnie do obliczeń AI.Dane przepływają przez procesor z mniejszą liczbą opóźnień, co pomaga zmniejszyć opóźnienia i zużycie energii.Staje się to szczególnie ważne w urządzeniach przenośnych, w których żywotność baterii i kontrola temperatury bezpośrednio wpływają na ogólną wydajność systemu.
W przeciwieństwie do układów ASIC o stałych funkcjach, które obsługują jedynie ograniczone obciążenia, jednostki NPU nadal zachowują poziom elastyczności.Dzięki optymalizacji oprogramowania i programowalnemu zachowaniu sprzętu mogą obsługiwać różne struktury sztucznej inteligencji i modele sieci neuronowych.Ta równowaga między wyspecjalizowaną akceleracją AI a możliwościami adaptacji pozwala NPU efektywnie działać w wielu nowoczesnych inteligentnych systemach, które wymagają szybkiego lokalnego przetwarzania AI.
Dlaczego jednostki NPU mają znaczenie w nowoczesnych systemach AI
Jedną z największych zalet NPU jest możliwość jednoczesnego przetwarzania wielu obliczeń.Sieci neuronowe w dużym stopniu zależą od powtarzających się operacji matematycznych na ogromnych zbiorach danych, a jednostka NPU rozdziela te operacje na wiele jednostek wykonawczych jednocześnie, zamiast przetwarzać je sekwencyjnie.To znacznie poprawia szybkość wnioskowania AI, przetwarzania obrazu i obliczeń sieci neuronowej.
Wewnętrzna struktura sprzętowa została również zaprojektowana specjalnie pod kątem obciążeń AI.Zamiast obsługiwać szeroką gamę zadań obliczeniowych ogólnego przeznaczenia, procesor koncentruje się na operacjach, z których korzystają najczęściej sieci neuronowe.Uproszczone rdzenie, zoptymalizowany dostęp do pamięci i dedykowane ścieżki instrukcji AI umożliwiają wydajniejsze przesyłanie danych, jednocześnie zmniejszając niepotrzebne obciążenie związane z przetwarzaniem.
Jednostki NPU poprawiają także wydajność poprzez wydajne obliczenia o niskiej precyzji.Wiele obciążeń AI nie wymaga niezwykle dużej precyzji numerycznej, aby uzyskać dokładne wyniki, dlatego jednostki NPU często używają formatów takich jak INT8 i FP16.Formaty te zmniejszają zużycie pamięci i koszty obliczeniowe, umożliwiając procesorowi wykonanie większej liczby operacji w krótszym czasie przy jednoczesnym zachowaniu wysokiej wydajności wnioskowania.
Wydajność energetyczna to kolejny główny powód, dla którego jednostki NPU stają się niezbędne w nowoczesnych urządzeniach.Ponieważ większość zasobów sprzętowych jest skupiona bezpośrednio na przetwarzaniu AI, znacznie mniej energii marnuje się na niepowiązane zadania.W porównaniu z tradycyjnymi procesorami CPU i GPU, jednostki NPU mogą wykonywać zadania AI przy znacznie mniejszym zużyciu energii.Jest to szczególnie cenne w smartfonach, urządzeniach elektronicznych do noszenia, inteligentnych aparatach, systemach IoT i sprzęcie brzegowym AI, gdzie ważna jest żywotność baterii i kontrola temperatury.
Jednostki NPU zmniejszają również obciążenie związane z dostępem do pamięci, umieszczając pamięć masową i obliczenia bliżej siebie w architekturze sprzętowej.W wielu tradycyjnych procesorach dane nieustannie przemieszczają się pomiędzy pamięcią a jednostkami obliczeniowymi, powodując opóźnienia i zwiększając zużycie energii.Krótsze wewnętrzne ścieżki danych zwiększają przepustowość i pomagają utrzymać stabilną wydajność podczas ciągłych obciążeń AI.
W miarę jak coraz więcej urządzeń integruje w sobie możliwości sztucznej inteligencji, jednostki NPU stają się coraz ważniejsze dla zapewnienia szybkiego czasu reakcji, wydajnego przetwarzania lokalnego i skalowalnej wydajności sztucznej inteligencji w kompaktowych systemach.Zadania takie jak wykrywanie obiektów w czasie rzeczywistym, interakcja głosowa, ulepszanie obrazu AI, inteligentne monitorowanie i przetwarzanie języka lokalnego mogą teraz być uruchamiane bezpośrednio na urządzeniach, bez nadmiernego polegania na chmurze obliczeniowej.
Architektura rdzenia i moduły przetwarzania NPU
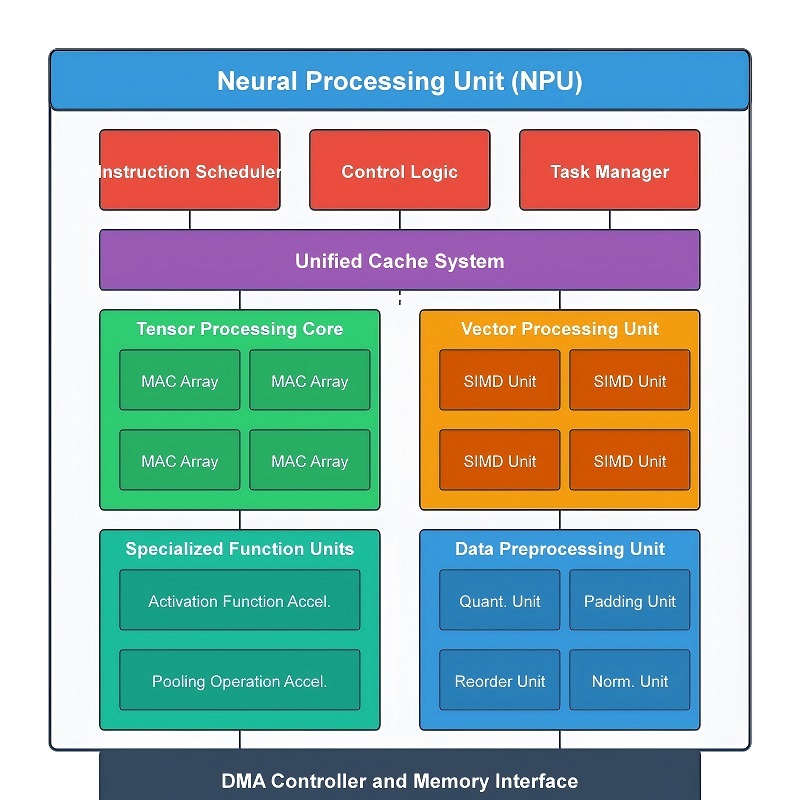
Jednostka NPU składa się z kilku wyspecjalizowanych modułów sprzętowych, które współpracują ze sobą w celu szybkiego i wydajnego przetwarzania obciążeń sieci neuronowej.Zamiast wysyłać każdą operację przez jeden procesor ogólnego przeznaczenia, obciążenie jest dzielone na dedykowane bloki sprzętowe, które w sposób ciągły i równoległy przetwarzają dane.Taka struktura poprawia szybkość wnioskowania AI, ogranicza niepotrzebne przenoszenie danych, zmniejsza zużycie energii i pomaga utrzymać efektywne wykorzystanie pamięci.
Podczas przetwarzania AI dane przepływają przez wiele etapów wewnątrz procesora.Dane wejściowe najpierw trafiają do potoku obliczeniowego, gdzie wykonywane są operacje matematyczne na dużą skalę.Wyniki pośrednie przechodzą następnie przez przetwarzanie aktywacyjne, akcelerację tensora, operacje związane z obrazem i sprzęt do optymalizacji pamięci, zanim zostanie wygenerowany ostateczny wynik.Ponieważ moduły te działają razem w skoordynowanej sekwencji, jednostka NPU może utrzymać wysoką przepustowość nawet podczas uruchamiania dużych modeli sieci neuronowych.
Podstawowe moduły obliczeniowe i aktywacyjne
Głównym silnikiem obliczeniowym wewnątrz NPU jest jednostka Multiply-Accumulate (MAC).Większość obciążeń sieci neuronowych wielokrotnie wykonuje mnożenie i dodawanie na bardzo dużych zbiorach danych, więc ten sprzęt obsługuje większość obliczeń AI podczas wnioskowania.Kiedy dane wejściowe trafiają do sieci neuronowej, wartości są mnożone przez zapisane wartości wagowe, a następnie sumowane w celu wygenerowania nowych wyników.Proces ten powtarza się w sposób ciągły w wielu warstwach sieci neuronowej.
Nowoczesne jednostki NPU często zawierają setki lub tysiące jednostek MAC działających jednocześnie.Zamiast obliczać jedną operację na raz, sprzęt rozdziela obciążenia na wiele równoległych ścieżek wykonania.Duże partie danych AI przepływają razem przez procesor, co znacznie poprawia szybkość wnioskowania przy jednoczesnym zachowaniu niskich opóźnień.Na przykład w systemach rozpoznawania obrazu jednostki MAC wielokrotnie skanują grupy pikseli i łączą wartości filtrów w celu wykrycia krawędzi, tekstur, kształtów i wzorów.W modelach językowych ten sam sprzęt wykonuje wielkoskalowe operacje wektorowe i macierzowe w celu przetwarzania tokenów i relacji między słowami.
Po zakończeniu tych obliczeń matematycznych wyniki są przenoszone do modułu funkcji aktywacji.Sieci neuronowe wykorzystują nieliniowe funkcje aktywacji do przetwarzania złożonych relacji w danych.Bez przetwarzania aktywacji sieć wykonywałaby jedynie proste obliczenia liniowe i nie byłaby w stanie skutecznie obsługiwać zaawansowanych zadań AI.
Moduł ten wykonuje funkcje takie jak ReLU, Sigmoid i Tanh bezpośrednio sprzętowo.Przychodzące wartości są szybko przekształcane zgodnie z wybraną regułą aktywacji.Na przykład ReLU usuwa wartości ujemne, zachowując jednocześnie dodatnie wyniki, pomagając sieci skupić się na silniejszych sygnałach cech podczas wnioskowania.Ponieważ przetwarzanie aktywacji odbywa się wielokrotnie w każdej warstwie sieci neuronowej, dedykowany sprzęt przyspieszający pomaga zmniejszyć opóźnienia i zapobiega przeciążeniu głównych jednostek obliczeniowych.
Moduły tensorowe i do przetwarzania danych przestrzennych
W skład jednostek NPU wchodzi także specjalistyczny sprzęt do obsługi operacji tensorowych i przetwarzania danych przestrzennych.Prawie każdy nowoczesny model sztucznej inteligencji opiera się na tensorach, czyli wielowymiarowych strukturach danych używanych do organizowania informacji według wymiarów, takich jak szerokość, wysokość, kanały, warstwy obiektowe i partie.Podczas wnioskowania duże ilości danych tensorowych stale przemieszczają się pomiędzy warstwami sieci neuronowej.
Jednostka przyspieszająca Tensor przetwarza te struktury tensorowe bezpośrednio na sprzęcie.Operacje takie jak mnożenie, przekształcanie, przekształcanie i akumulacja tensora są wykonywane znacznie szybciej niż na procesorach ogólnego przeznaczenia.To dedykowane przyspieszenie staje się szczególnie ważne w architekturach transformatorów, komputerowych systemach wizyjnych, dużych modelach językowych i aplikacjach AI czasu rzeczywistego, które wymagają bardzo dużej przepustowości.
Oprócz przetwarzania tensorowego jednostki NPU zawierają także moduły przeznaczone do operacji na danych 2D i przestrzennych, powszechnie stosowanych w obciążeniach związanych z obrazami i wideo.Komputerowe systemy wizyjne stale zmieniają rozmiar, reorganizują, filtrują i przenoszą duże ilości danych pikseli, zanim rozpocznie się głębsza analiza AI.Wykonywanie tych zadań oddzielnie poprawia wydajność i zmniejsza obciążenie głównego silnika obliczeniowego.
Podczas przetwarzania obrazu sprzęt zarządza operacjami, takimi jak próbkowanie w dół, przesuwanie mapy obiektów, kopiowanie obrazu, zmiana rozmiaru, kadrowanie i przesyłanie danych przestrzennych.Na przykład wideo o wysokiej rozdzielczości zarejestrowane przez kamerę może najpierw zostać zmienione i zreorganizowane przed wprowadzeniem do sieci neuronowej.Zmniejsza to obciążenie obliczeniowe, zachowując jednocześnie ważne informacje wizualne potrzebne do wykrywania obiektów i analizy sceny.
Moduły optymalizacji pamięci i kompresji danych
Nowoczesne modele sztucznej inteligencji wymagają dużej ilości pamięci do przechowywania wag sieci neuronowych, tensorów i danych pośrednich.Ciągłe przesyłanie tych informacji między pamięcią a sprzętem komputerowym zwiększa wykorzystanie przepustowości, opóźnienia i zużycie energii.Aby zmniejszyć ten narzut, jednostki NPU zawierają dedykowane moduły kompresji i dekompresji danych.
Zanim dane zostaną zapisane w pamięci, powtarzające się wzory i wartości wag są kompresowane do mniejszych formatów.Podczas wykonywania skompresowane informacje są szybko przywracane i wysyłane bezpośrednio do potoku obliczeniowego.Zmniejsza to obciążenie pamięci i pozwala na przechowywanie większej ilości danych AI w szybkiej pamięci lokalnej, bliżej procesora.
Zaawansowane metody kompresji często pozwalają kilkukrotnie zmniejszyć rozmiar modelu, zachowując niemal tę samą dokładność wnioskowania.Staje się to szczególnie ważne w przypadku smartfonów, systemów wbudowanych, inteligentnych kamer, elektroniki do noszenia i innych urządzeń brzegowych AI, w których pojemność pamięci i efektywność energetyczna są ograniczone.
Jak te moduły współpracują ze sobą
Wydajność NPU nie zależy od pojedynczego bloku sprzętowego.Jego wydajność wynika ze współdziałania wszystkich modułów przetwarzania w ramach skoordynowanego potoku.
Typowe obciążenie AI zaczyna się od obliczeń matematycznych na dużą skalę w jednostkach MAC.Wyniki pośrednie przechodzą następnie przez przetwarzanie aktywacyjne w celu wprowadzenia nieliniowego zachowania do sieci neuronowej.Sprzęt akcelerujący Tensor w sposób ciągły organizuje i przetwarza wielowymiarowe dane w całym potoku, podczas gdy moduły przetwarzania przestrzennego zarządzają operacjami związanymi z obrazami i wideo.Jednocześnie sprzęt kompresujący zmniejsza obciążenie związane z przesyłaniem pamięci w tle.
Ponieważ operacje te przebiegają jednocześnie na dedykowanych ścieżkach sprzętowych, jednostka NPU może przetwarzać duże obciążenia AI z dużą przepustowością, mniejszymi opóźnieniami i znacznie lepszą efektywnością energetyczną niż tradycyjne procesory.
NPU w smartfonach i mobilna sztuczna inteligencja
Nowoczesne smartfony w każdej sekundzie wykonują ogromną liczbę operacji.Telefon można odblokowywać za pomocą rozpoznawania twarzy, otwierać aparat, przetwarzać zdjęcia, tłumaczyć mowę i niemal natychmiast uruchamiać aplikacje wspomagane sztuczną inteligencją.Aby zapewnić ten poziom wydajności w cienkich urządzeniach mobilnych o ograniczonej pojemności baterii, smartfony opierają się na wysoce zintegrowanych architekturach System-on-Chip (SoC).
Wewnątrz SoC wiele procesorów współpracuje ze sobą, a każdy procesor jest zoptymalizowany pod kątem innego obciążenia.Procesor zarządza kontrolą systemu, aplikacjami i ogólnymi zadaniami obliczeniowymi.Procesor graficzny obsługuje renderowanie grafiki, gry i przetwarzanie obrazu.NPU (jednostka przetwarzania neuronowego) koncentruje się szczególnie na obliczeniach AI.
Zamiast kierować obciążenia sieci neuronowej przez procesor lub procesor graficzny, smartfony kierują wiele zadań AI do NPU, gdzie sprzęt jest zoptymalizowany pod kątem szybkiego równoległego przetwarzania AI.To oddzielenie poprawia wydajność, ponieważ każdy procesor radzi sobie z typem obciążenia, dla którego został zaprojektowany.W rezultacie smartfony mogą wykonywać zaawansowane operacje AI z krótszym czasem reakcji, mniejszymi opóźnieniami i lepszą wydajnością energetyczną.
Jak jednostki NPU zmieniły sztuczną inteligencję smartfonów
Zanim mobilne jednostki NPU stały się powszechne, wiele funkcji sztucznej inteligencji smartfonów w dużym stopniu zależało od przetwarzania w chmurze.Zadania takie jak rozpoznawanie głosu, tłumaczenie językowe, ulepszanie obrazu i inteligentni asystenci często wymagały przesłania danych na zdalne serwery w celu przetworzenia, zanim wyniki zostaną zwrócone do urządzenia.Spowodowało to opóźnienia, zwiększony ruch w sieci i wzbudziło obawy dotyczące prywatności.
Wprowadzenie dedykowanych mobilnych jednostek NPU znacząco zmieniło ten przepływ pracy.Modele AI mogły teraz działać bezpośrednio na samym smartfonie, umożliwiając wykonywanie wielu operacji lokalnie w czasie rzeczywistym, zamiast całkowicie polegać na serwerach zewnętrznych.
Ta zmiana zapewniła kilka głównych korzyści:
• Mniejsze opóźnienia, ponieważ dane nie wymagają już ciągłej komunikacji w chmurze
• Szybszy czas reakcji AI podczas operacji w czasie rzeczywistym
• Lepsza ochrona prywatności, ponieważ wrażliwe dane mogą pozostać na urządzeniu
• Niższe zużycie energii dzięki sprzętowi zoptymalizowanemu specjalnie pod kątem obciążeń AI
• Bardziej stabilna wydajność AI nawet przy słabych lub niedostępnych połączeniach internetowych
W miarę jak mobilne jednostki NPU stawały się coraz potężniejsze, na smartfonach zaczęto stale uruchamiać zaawansowane funkcje AI w tle, bez zauważalnych opóźnień podczas codziennego użytkowania.
Jak smartfony wykorzystują NPU w rzeczywistych operacjach
Fotografia AI i przetwarzanie obrazu
Jednym z najbardziej widocznych zastosowań mobilnych NPU jest fotografia AI.Nowoczesne aparaty w smartfonach nie opierają się już wyłącznie na czujnikach obrazu i tradycyjnych algorytmach przetwarzania obrazu.Modele AI analizują teraz dane obrazu w sposób ciągły podczas pracy aparatu.
Po otwarciu aplikacji aparatu smartfon natychmiast rozpoczyna przetwarzanie przychodzącego strumienia obrazu klatka po klatce.NPU analizuje w czasie rzeczywistym warunki oświetleniowe, granice obiektów, szczegóły twarzy, kolory, tekstury i wzorce ruchu.Na podstawie tej analizy system niemal natychmiast przed wykonaniem zdjęcia dostosowuje ekspozycję, balans bieli, ustawienia HDR, ostrość i kontrast.
W fotografii przy słabym oświetleniu NPU łączy wiele klatek obrazu, aby poprawić jasność, jednocześnie redukując szumy wizualne.Podczas fotografii portretowej procesor oddziela obiekty na pierwszym planie od obszarów tła i dokładniej stosuje efekty głębi wokół krawędzi, takich jak włosy, okulary i kontury odzieży.
Rozpoznawanie scen zależy również w dużym stopniu od NPU.Procesor porównuje wzorce obrazów z wyszkolonymi modelami sztucznej inteligencji, aby zidentyfikować środowiska, takie jak żywność, krajobrazy, zwierzęta, dokumenty, zachody słońca lub sceny nocne.Po rozpoznaniu aparat automatycznie dostosowuje ustawienia w celu optymalizacji jakości obrazu.
Ponieważ obliczenia te odbywają się bezpośrednio na smartfonie, fotografowanie sztuczną inteligencją wydaje się niemal natychmiastowe, mimo że w tle stale wykonywane są duże ilości obliczeń sieci neuronowej.
Rozpoznawanie głosu i asystenci AI
Asystenci głosowi i funkcje związane z mową również w dużym stopniu opierają się na lokalnym przyspieszeniu sztucznej inteligencji.Kiedy użytkownik rozmawia ze smartfonem, mikrofon przechwytuje surowe sygnały audio, które należy oczyścić, oddzielić i przekształcić w rozpoznawalne wzorce mowy.
NPU w sposób ciągły przetwarza strumień audio, identyfikując fonemy, filtrując szum tła i dopasowując wzorce dźwiękowe do modeli rozpoznawania mowy.Lokalne przetwarzanie AI umożliwia niemal natychmiastowe wykrywanie słów aktywacji i typowych poleceń głosowych, bez konieczności ciągłego przesyłania nagrań audio do serwerów w chmurze.
Poprawia to szybkość reakcji w przypadku zadań takich jak:
• Polecenia głosowe
• Transkrypcja mowy w czasie rzeczywistym
• Tłumaczenie językowe
• Interakcja asystenta AI
• Udoskonalenie połączeń AI
• Tłumienie szumów podczas rozmów wideo
Ponieważ znaczna część przetwarzania odbywa się bezpośrednio na urządzeniu, interakcja głosowa pozostaje płynniejsza nawet w niestabilnych warunkach sieci.
Gry AI i optymalizacja systemu w czasie rzeczywistym
Nowoczesne smartfony wykorzystują także NPU do optymalizacji gier i inteligentnego zarządzania systemami.Podczas rozgrywki modele AI monitorują w czasie rzeczywistym zapotrzebowanie na renderowanie klatek, zachowanie obciążenia, warunki termiczne, wzorce wprowadzania dotykowego i zużycie baterii.
System może dynamicznie dostosowywać obciążenie procesora graficznego, optymalizować alokację mocy, stabilizować liczbę klatek na sekundę i zmniejszać przegrzanie podczas długich sesji grania.Niektóre smartfony korzystają również z technik zwiększania skali AI i przewidywania ruchu, aby poprawić płynność obrazu przy jednoczesnym niższym zużyciu energii.
Poza grami jednostka NPU pomaga optymalizować aplikacje działające w tle, zarządzać baterią, przewidywać interakcje z użytkownikiem i planować zadania w oparciu o wzorce użytkowania urządzenia.
Ewolucja mobilnych jednostek NPU
Rozwój mobilnych jednostek NPU gwałtownie przyspieszył, ponieważ obciążenia AI smartfonów stały się bardziej zaawansowane i wymagające obliczeniowo.
|
Okres |
Rozwój mobilnych NPU |
|
2017 — Wczesne komercyjne mobilne jednostki NPU |
Huawei wprowadził na rynek jeden z pierwszych komercyjnych smartfonów
NPU poprzez procesor Kirin 970.Oznaczało to poważną zmianę w kierunku
przyspieszenie sztucznej inteligencji na dużą skalę w smartfonach konsumenckich.Zamiast
polegając głównie na procesorach i procesorach graficznych w zadaniach AI, włączając teraz smartfony
dedykowany sprzęt AI bezpośrednio w architekturze SoC. |
|
2018 — Rozbudowa sztucznej inteligencji na urządzeniu |
Apple wprowadził silnik neuronowy do wnętrza A12 Bionic
chip, usprawniający przetwarzanie AI do rozpoznawania twarzy, obliczeniowy
fotografii i inteligentnych funkcji mobilnych.Sztuczna inteligencja na urządzeniach stała się głównym tematem
skupić się na rozwoju flagowych smartfonów. |
|
2019–2020 — Integracja sztucznej inteligencji w całej branży |
Główni producenci chipów, w tym Qualcomm, Samsung i
MediaTek rozpoczął integrację dedykowanych akceleratorów AI z flagowymi urządzeniami mobilnymi
procesory.Wydajność sztucznej inteligencji zaczęła stawać się głównym czynnikiem konkurencyjności
projekt sprzętu smartfona. |
|
2021–2023 — Przetwarzanie sztucznej inteligencji staje się głównym punktem odniesienia |
Producenci smartfonów coraz częściej porównywali NPU
wydajność obok wydajności procesora i karty graficznej.NPU stały się centralnym punktem
fotografia obliczeniowa, głosowa sztuczna inteligencja, ulepszanie wideo, optymalizacja baterii,
i inteligentne funkcje systemu. |
|
2024–2025 — Duże modele AI działające na smartfonach |
Nowoczesne mobilne procesory NPU zyskały wystarczającą moc obliczeniową, aby
obsługuje większe modele AI bezpośrednio na smartfonach i urządzeniach brzegowych.Więcej sztucznej inteligencji
obciążenia mogą teraz działać lokalnie, bez dużej zależności od chmury
infrastruktury, poprawiając zarówno responsywność, jak i prywatność. |
Porównanie obecnych głównych mobilnych jednostek NPU
Nowoczesne flagowe procesory do smartfonów zawierają teraz wysoce zaawansowane architektury NPU zoptymalizowane pod kątem wnioskowania AI w czasie rzeczywistym, wysokiej przepustowości i zwiększonej efektywności energetycznej.
|
Procesor mobilny |
Funkcje NPU |
|
Apple A17Pro |
Zawiera 26-rdzeniowy silnik neuronowy zaprojektowany z myślą o szybkości
przetwarzanie AI na urządzeniu.Architektura poprawia fotografię AI i głos
rozpoznawanie i inteligentne funkcje systemu działające w czasie rzeczywistym na urządzeniach Apple. |
|
Qualcomm Snapdragon 8 Gen 3 |
Wykorzystuje ulepszony procesor Hexagon AI zoptymalizowany pod kątem
generatywna sztuczna inteligencja, przyspieszenie sieci neuronowej, zaawansowane przetwarzanie obrazu i
wydajne mobilne obciążenia AI. |
|
MediaTek Dimensity 9300 |
Zawiera APU (jednostkę przetwarzającą AI) szóstej generacji z
znaczne ulepszenia szybkości wnioskowania AI i przetwarzania AI w czasie rzeczywistym
możliwości dla smartfonów i urządzeń brzegowych. |
|
Samsunga Exynosa 2400 |
Zawiera mobilną jednostkę NPU nowej generacji, skupiającą się na szybkości
Przetwarzanie AI na urządzeniu do fotografii obliczeniowej, inteligentny system
operacji i zaawansowanych aplikacji mobilnych AI. |
NPU vs GPU vs CPU: kluczowe różnice w przetwarzaniu AI
Zarówno procesory graficzne, jak i NPU są zaprojektowane do równoległego przetwarzania dużych ilości danych, ale zostały zbudowane do zupełnie innych celów.Procesor graficzny został pierwotnie opracowany do renderowania grafiki, natomiast procesor NPU został stworzony specjalnie do obliczeń w sieciach neuronowych i wnioskowania AI.
Ze względu na tę różnicę w celach projektowych oba procesory radzą sobie z obciążeniami AI w bardzo różny sposób.Procesory graficzne mogą skutecznie uruchamiać modele sztucznej inteligencji, szczególnie w wielkoskalowych systemach szkoleniowych, ale nadal charakteryzują się dużą złożonością procesora graficznego.Jednostki NPU upraszczają wiele z tych operacji, koncentrując się prawie wyłącznie na obliczeniach związanych ze sztuczną inteligencją.
Jak procesory graficzne radzą sobie z obciążeniami AI
Procesor graficzny (Graphics Processing Unit) został po raz pierwszy zaprojektowany do przetwarzania danych graficznych, takich jak tekstury, efekty świetlne, przekształcenia geometryczne i renderowanie obrazu.Aby obsłużyć te obciążenia, procesory graficzne zawierają tysiące równoległych rdzeni przetwarzających, które mogą obsługiwać wiele operacji jednocześnie.
Wraz ze wzrostem obciążenia AI do uczenia i wnioskowania sieci neuronowych zaczęto wykorzystywać procesory graficzne, ponieważ sprzęt obsługiwał już przetwarzanie równoległe na dużą skalę.Operacje macierzowe wykorzystywane w głębokim uczeniu się mogą być rozproszone na wiele rdzeni GPU, znacznie zwiększając prędkość przetwarzania w porównaniu z procesorami CPU.
Jednak ogólna koordynacja procesorów graficznych nadal w dużym stopniu zależy od procesora.Podczas przetwarzania AI procesor zazwyczaj zarządza:
• Planowanie zadań
• Alokacja pamięci
• Przenoszenie danych
• Kontrola instrukcji
• Koordynacja na poziomie systemu
Typowe obciążenie AI na GPU obejmuje ciągłą komunikację pomiędzy procesorem, pamięcią GPU i jednostkami obliczeniowymi.Dane są wielokrotnie przesyłane pomiędzy buforami pamięci, systemami pamięci podręcznej i rdzeniami wykonawczymi, zanim wyniki zostaną zwrócone do następnego etapu przetwarzania.
Ten przepływ pracy jest potężny, ale zwiększa również:
• Zużycie energii
• Wykorzystanie przepustowości pamięci
• Narzut związany z przesyłaniem danych
• Złożoność systemu
• Wytwarzanie ciepła
W serwerach o wysokiej wydajności ograniczenia te można pokonać za pomocą dużych systemów chłodzenia i wysokiej dostępności energii elektrycznej.Jednak w przypadku urządzeń mobilnych lub brzegowych to samo podejście staje się znacznie mniej wydajne.
Jak jednostki NPU wydajniej przetwarzają sztuczną inteligencję
Jednostka NPU (jednostka przetwarzania neuronowego) jest zbudowana specjalnie w oparciu o rzeczywistą strukturę obliczeń sieci neuronowej.Zamiast obsługiwać szeroką gamę operacji graficznych lub ogólnego przeznaczenia, sprzęt koncentruje się prawie całkowicie na wnioskowaniu AI i przetwarzaniu tensorowym.
Podczas wykonywania AI dane sieci neuronowej przepływają przez dedykowane ścieżki sprzętowe zoptymalizowane pod kątem takich operacji jak:
• Mnożenie macierzy
• Splot
• Przyspieszenie tensorowe
• Ekstrakcja cech
• Obliczenia równoległej sieci neuronowej
W przeciwieństwie do procesorów graficznych, jednostki NPU wykorzystują wysoce zoptymalizowane zestawy instrukcji AI przeznaczone bezpośrednio do operacji głębokiego uczenia się.Zmienia to sposób wykonywania obciążeń na poziomie sprzętu.
Na przykład procesor graficzny może wymagać wielu warstw planowania instrukcji i obsługi pamięci, aby wykonać zadanie sieci neuronowej.Jednostka NPU może często wykonać tę samą operację przy użyciu znacznie mniejszej liczby instrukcji, ponieważ potok sprzętowy jest już zgodny ze strukturą obliczeń AI.
Redukuje to niepotrzebne etapy przetwarzania i poprawia:
• Szybkość wnioskowania
• Efektywność energetyczna
• Reakcja w czasie rzeczywistym
• Przepustowość dla obciążeń AI
Rezultatem jest szybsze lokalne przetwarzanie AI przy niższym obciążeniu sprzętowym.
Różnice w przesyłaniu danych
Jedną z największych różnic między procesorami graficznymi i jednostkami NPU jest sposób, w jaki dane przemieszczają się przez procesor podczas obliczeń.
Przepływ danych GPU
W systemie opartym na GPU dane stale przemieszczają się pomiędzy:
• Bufory pamięci
• Warstwy pamięci podręcznej
• Rdzenie przetwarzające
• Zewnętrzne systemy pamięci
Duże modele sztucznej inteligencji wymagają ciągłego przesyłania ogromnych ilości danych tensorowych przez sprzęt.Każdy transfer zużywa przepustowość i energię, jednocześnie powodując opóźnienia.
Podczas działania sieci neuronowej wagi i wyniki pośrednie są wielokrotnie ładowane z pamięci, przetwarzane, a następnie ponownie zapisywane w celu następnego etapu obliczeń.Wraz ze wzrostem rozmiaru modelu, głównym wąskim gardłem staje się ruch w pamięci.
Przepływ danych NPU
Jednostki NPU zmniejszają ten narzut, umieszczając pamięć i obliczenia bliżej siebie w architekturze sprzętowej.Wiele projektów NPU wykorzystuje struktury przetwarzania inspirowane przepływem danych w sieci neuronowej, gdzie obliczenia i obsługa wag pozostają ze sobą ściśle powiązane przez cały czas wykonywania.
Zamiast wielokrotnie przenosić duże ilości danych długimi ścieżkami sprzętowymi, procesor przechowuje więcej informacji w pobliżu jednostek wykonawczych.Wyniki pośrednie można przenosić bezpośrednio między wyspecjalizowanymi modułami przy mniejszej liczbie operacji dostępu do pamięci.
Ta krótsza i bardziej wydajna ścieżka danych poprawia:
• Przepustowość
• Opóźnienie
• Wydajność przepustowości
• Zużycie energii
Ulepszenie staje się szczególnie istotne podczas ciągłego wnioskowania AI na urządzeniach mobilnych i brzegowych.
Efektywność energetyczna i wydajność cieplna
Wydajność energetyczna jest jedną z najmocniejszych zalet jednostek NPU.
Wysokowydajne procesory graficzne zużywają duże ilości energii elektrycznej, ponieważ zawierają ogromne zasoby obliczeń równoległych przeznaczone do renderowania grafiki i obliczeń na dużą skalę.Przy dużych obciążeniach procesory graficzne również generują znaczne ciepło i często wymagają zaawansowanych systemów chłodzenia, takich jak rurki cieplne, komory parowe lub aktywne wentylatory.
W przypadku stacjonarnych stacji roboczych i serwerów AI wymagania te są możliwe do spełnienia, ponieważ przestrzeń i moc są mniej ograniczone.Smartfony, urządzenia do noszenia, inteligentne kamery i systemy IoT działają w bardzo różnych warunkach.
Urządzenia mobilne muszą utrzymywać:
• Długi czas pracy baterii
• Stabilny poziom temperatury
• Kompaktowy rozmiar sprzętu
• Cicha praca
• Ciągła reakcja w czasie rzeczywistym
Jednostki NPU zaprojektowano z myślą o tych ograniczeniach.Ponieważ sprzęt koncentruje się w szczególności na wnioskowaniu AI, mniej zasobów jest marnowanych na niepowiązane operacje.Procesor może wykonywać zadania sieci neuronowej przy znacznie niższym zużyciu energii w porównaniu do procesorów graficznych.
To sprawia, że NPU doskonale nadają się do:
• Smartfony
• Przenośna elektronika
• Inteligentne kamery
• Urządzenia do noszenia
• Czujniki autonomiczne
• Systemy Edge AI
• Sprzęt IoT zasilany bateryjnie
Różne role procesorów graficznych i NPU
Chociaż jednostki NPU zapewniają znaczne korzyści w zakresie wnioskowania AI, procesory graficzne nadal pozostają niezwykle ważne w wielu środowiskach obliczeniowych.
Gdzie procesory graficzne działają najlepiej
Procesory graficzne są bardzo skuteczne w:
• Renderowanie grafiki
• Symulacja naukowa
• Modelowanie 3D
• Przetwarzanie wideo
• Szkolenia AI na dużą skalę
• Obliczenia w centrum danych
• Obciążenia obliczeniowe o wysokiej wydajności
Uczenie dużych sieci neuronowych wymaga ogromnej elastyczności obliczeniowej i możliwości przetwarzania zmiennoprzecinkowego, z którymi procesory graficzne radzą sobie bardzo dobrze.
Gdzie jednostki NPU radzą sobie najlepiej
NPU są zoptymalizowane głównie pod kątem:
• Wnioskowanie AI w czasie rzeczywistym
• Lokalne przetwarzanie AI
• Inteligentne systemy małej mocy
• Obciążenia Edge AI
• Przyspieszenie mobilnej AI
• Ciągłe zadania AI w tle
Zamiast trenować ogromne modele, jednostki NPU skupiają się na wydajnym uruchamianiu wyszkolonych modeli w kompaktowych urządzeniach.
Dzięki temu smartfony, aparaty fotograficzne, pojazdy, systemy robotyki i inteligentna elektronika mogą wykonywać operacje AI lokalnie z krótkim czasem reakcji i mniejszą zależnością od serwerów w chmurze.
Dlaczego NPU stają się coraz ważniejsze
W miarę jak funkcje sztucznej inteligencji stają się częścią urządzeń codziennego użytku, zapotrzebowanie na wydajne lokalne przetwarzanie sztucznej inteligencji stale rośnie.Użytkownicy oczekują obecnie, że smartfony i urządzenia inteligentne będą wykonywać takie zadania, jak:
• Tłumaczenie językowe w czasie rzeczywistym
• Ulepszanie fotografii AI
• Interakcja głosowa
• Rozpoznawanie twarzy
• Inteligentna analiza wideo
• Wykrywanie obiektów
• Spersonalizowane rekomendacje
Te obciążenia wymagają szybkiego wnioskowania przy małych opóźnieniach i kontrolowanym zużyciu energii.
Procesory graficzne pozostają niezbędne w infrastrukturze obliczeniowej o wysokiej wydajności i infrastrukturze szkoleniowej AI, ale jednostki NPU stają się preferowanym rozwiązaniem do przyspieszania sztucznej inteligencji na urządzeniach i inteligencji brzegowej w czasie rzeczywistym.
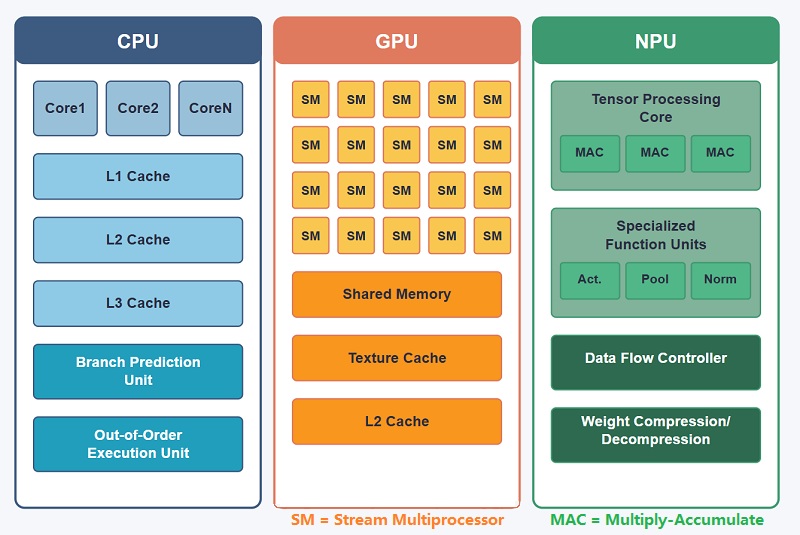
Wyspecjalizowane jednostki przetwarzające w nowoczesnej informatyce
Nowoczesne systemy komputerowe wykorzystują wiele różnych typów procesorów, ponieważ żadna pojedyncza architektura nie jest w stanie skutecznie obsłużyć każdego obciążenia.Niektóre procesory koncentrują się na kontroli systemu, inne specjalizują się w renderowaniu grafiki, a inne są zoptymalizowane pod kątem akceleracji AI, pracy w sieci, obliczeń naukowych lub kontroli wbudowanej.
W nowoczesnych smartfonach, serwerach, systemach przemysłowych, platformach robotyki, pojazdach i urządzeniach brzegowych AI wiele jednostek przetwarzających często współpracuje jednocześnie.Każdy procesor radzi sobie z typem obciążenia, dla którego został specjalnie zaprojektowany, poprawiając wydajność, efektywność energetyczną i responsywność w czasie rzeczywistym we współczesnych środowiskach komputerowych.
Procesor: Jednostka centralna
Procesor (Central Processing Unit) jest głównym kontrolerem większości systemów komputerowych.Zarządza systemami operacyjnymi, aplikacjami, koordynacją pamięci, planowaniem zadań i komunikacją pomiędzy komponentami sprzętowymi.
Procesory są bardzo elastyczne i mogą niezawodnie obsługiwać wiele różnych obciążeń, co czyni je niezbędnymi w komputerach, smartfonach, serwerach i systemach wbudowanych.Są jednak mniej wydajne w przypadku równoległych obciążeń AI na dużą skalę w porównaniu z bardziej wyspecjalizowanymi procesorami.
GPU: Jednostka przetwarzania grafiki
Procesor graficzny (jednostka przetwarzania grafiki) jest zoptymalizowany pod kątem przetwarzania równoległego na dużą skalę.Architektura zawiera wiele rdzeni wykonawczych, które są w stanie obsłużyć tysiące operacji jednocześnie.
Procesory graficzne zostały pierwotnie opracowane do renderowania grafiki, ale obecnie są szeroko stosowane do szkolenia sztucznej inteligencji, symulacji naukowych, przetwarzania wideo i obliczeń o wysokiej wydajności ze względu na ich duże możliwości obliczeń równoległych.
NPU: jednostka przetwarzania neuronowego
Jednostka NPU (jednostka przetwarzania neuronowego) została zaprojektowana specjalnie do przyspieszania sieci neuronowych i wnioskowania AI.Sprzęt koncentruje się na obliczeniach tensorowych, mnożeniu macierzy, operacjach splotu i przetwarzaniu AI o niskim poborze mocy.
Jednostki NPU są powszechnie stosowane w smartfonach, inteligentnych aparatach, brzegowych systemach AI, robotyce i inteligentnych urządzeniach, gdzie ważne jest szybkie lokalne przetwarzanie AI i efektywność energetyczna.
TPU: Jednostka przetwarzająca tensor
TPU (Tensor Processing Unit) jest zoptymalizowany pod kątem obciążeń AI opartych na tensorach i przyspieszenia głębokiego uczenia się na dużą skalę.Procesory te są przeznaczone głównie dla infrastruktury AI w chmurze i środowisk uczenia maszynowego w centrach danych.
TPU są bardzo skuteczne w:
• Szkolenie w zakresie głębokiego uczenia się
• Duże modele AI
• Obliczenia tensorowe
• Usługi AI w chmurze
• Wysokoprzepustowe przyspieszenie AI
FPGA: rekonfigurowalne przetwarzanie sprzętowe
Układ FPGA (Field-Programmable Gate Array) wykorzystuje programowalne bloki logiczne, które można skonfigurować do określonych zadań po wyprodukowaniu.W przeciwieństwie do architektur ze stałymi procesorami, układy FPGA umożliwiają dostosowanie samych funkcji sprzętowych.
Układy FPGA są szeroko stosowane w:
• Systemy komunikacji
• Elektronika samochodowa
• Automatyka przemysłowa
• Systemy lotnicze
• Przetwarzanie brzegowe
• Urządzenia medyczne
DPU: Jednostka Przetwarzania Danych
Jednostka DPU (Data Processing Unit) jest zoptymalizowana pod kątem obciążeń skoncentrowanych na danych w infrastrukturze chmury i systemach sieciowych.Jednostki DPU pomagają zmniejszyć obciążenie procesora, przyspieszając przenoszenie danych, operacje przechowywania, szyfrowanie i zarządzanie ruchem sieciowym.
Procesory te są powszechnie stosowane w:
• Centra danych
• Przetwarzanie w chmurze
• Szybka sieć
• Przyspieszenie przechowywania
• Infrastruktura serwerowa
VPU: Jednostka przetwarzania obrazu
VPU (Vision Processing Unit) specjalizuje się w przetwarzaniu obrazu komputerowego i sztucznej inteligencji opartej na obrazach.Jednostki VPU przyspieszają takie zadania, jak rozpoznawanie twarzy, wykrywanie obiektów, śledzenie ruchu i analiza wideo.
VPU są powszechnie spotykane w:
• Inteligentne kamery
• Systemy nadzoru
• Robotyka
• Pojazdy autonomiczne
• Systemy AR/VR
• Urządzenia wizyjne Edge AI
IPU: Jednostka Przetwarzania Inteligencji
Jednostka IPU (jednostka przetwarzania inteligencji) została zaprojektowana z myślą o wysoce równoległych obciążeniach związanych ze sztuczną inteligencją i uczeniem maszynowym.Architektura skupia się na poprawie efektywności przepływu danych podczas realizacji sieci neuronowej na dużą skalę.
IPU służą do:
• Przyspieszenie uczenia maszynowego
• Rozpoznawanie wzorców
• Wnioskowanie AI
• Równoległe przetwarzanie tensorowe
• Zaawansowane badania nad sztuczną inteligencją
BPU: Jednostka przetwarzania mózgu
Jednostka BPU (Brain Processing Unit) jest zoptymalizowana pod kątem wbudowanych systemów AI i inteligencji brzegowej.Procesory te skupiają się na szybkim lokalnym wnioskowaniu AI przy niższym zużyciu energii.
Procesory BPU są powszechnie stosowane w:
• Inteligentne systemy wykrywania
• Robotyka
• Sprzęt Edge AI
• Systemy detekcji ruchu
• Platformy autonomiczne
HPU: Jednostka przetwarzania holograficznego
HPU (Holographic Processing Unit) jest przeznaczony do systemów obliczeń holograficznych, rzeczywistości mieszanej i analizy przestrzennej.
Proces pomocy HPU:
• Mapowanie środowiska
• Śledzenie ruchu
• Fuzja czujników
• Interakcja przestrzenna w czasie rzeczywistym
• Środowiska AR/VR
MPU i MCU: Wbudowane przetwarzanie sterujące
MPU (jednostki mikroprocesorowe) i MCU (jednostki mikrokontrolera) są szeroko stosowane w systemach wbudowanych i elektronice małej mocy.
Jednostki MPU są powszechnie stosowane we wbudowanych systemach komputerowych, które wymagają kontroli na poziomie systemu operacyjnego, natomiast jednostki MCU integrują rdzenie procesorów, pamięć i sterowanie wejściami/wyjściami w kompaktowym chipie do dedykowanych zadań wymagających niskiego poboru mocy.
Te procesory są powszechnie spotykane w:
• Urządzenia IoT
• Sterowniki przemysłowe
• Elektronika samochodowa
• Urządzenia gospodarstwa domowego
• Przenośne systemy wbudowane
APU: jednostka przyspieszonego przetwarzania
Jednostka APU (Accelerated Processing Unit) łączy funkcjonalność procesora i procesora graficznego w jednym pakiecie procesora.Integracja ta poprawia efektywność energetyczną, zmniejsza rozmiar sprzętu i pozwala obciążeniom obliczeniowym i graficznym na bardziej efektywne współdzielenie zasobów systemowych.
APU są powszechnie stosowane w:
• Laptopy
• Minikomputery
• Podstawowe systemy gier
• Urządzenia multimedialne
• Przenośne platformy komputerowe
Dlaczego nowoczesne systemy korzystają z wielu wyspecjalizowanych procesorów
Nowoczesne systemy komputerowe rzadko opierają się na architekturze jednoprocesorowej.Zamiast tego urządzenia łączą ze sobą wiele wyspecjalizowanych procesorów, ponieważ różne obciążenia wymagają różnych metod przetwarzania.
Na przykład nowoczesny system może wykorzystywać:
• Procesory do sterowania systemem
• Procesory graficzne do grafiki i obliczeń równoległych
• Jednostki NPU do wnioskowania AI
• Jednostki VPU do widzenia komputerowego
• Jednostki DPU do obsługi sieci i przesyłania danych
• MCU do wbudowanych zadań kontrolnych
Rozdzielając obciążenia pomiędzy dedykowany sprzęt, nowoczesne systemy osiągają lepszą wydajność, mniejsze opóźnienia, lepszą efektywność energetyczną i bardziej efektywne przetwarzanie w czasie rzeczywistym w środowiskach AI, graficznych, sieciowych i wbudowanych.
Praktyczne zastosowania NPU

Jednostki NPU są obecnie stosowane w szerokiej gamie inteligentnych systemów, ponieważ nowoczesne obciążenia AI w coraz większym stopniu wymagają szybkiego przetwarzania lokalnego zamiast ciągłej komunikacji w chmurze.Uruchamiając wnioskowanie sieci neuronowej bezpośrednio na sprzęcie lokalnym, urządzenia mogą szybciej reagować, zmniejszać wykorzystanie przepustowości, poprawiać prywatność i utrzymywać stabilną wydajność w czasie rzeczywistym nawet w ograniczonych warunkach sieciowych.
W miarę jak modele sztucznej inteligencji stawały się mniejsze i bardziej wydajne, jednostki NPU rozszerzyły się daleko poza smartfony i systemy badawcze na automatyzację przemysłową, robotykę, urządzenia opieki zdrowotnej, infrastrukturę sieciową, maszyny autonomiczne, inteligentne kamery, platformy IoT i brzegowe systemy AI.Ich zdolność do ciągłego przetwarzania obciążeń AI przy niższym zużyciu energii i mniejszych opóźnieniach sprawia, że są one bardzo cenne w nowoczesnych środowiskach obliczeniowych czasu rzeczywistego.
NPU w smartfonach i urządzeniach konsumenckich
Smartfony pozostają jednym z najczęstszych przykładów integracji NPU.Nowoczesne urządzenia mobilne wykorzystują procesory NPU do fotografii AI, asystentów głosowych, przetwarzania języka, optymalizacji gier, ulepszania obrazu i inteligentnego zarządzania baterią.
Na przykład aparaty w smartfonach wykorzystują jednostki NPU do analizowania warunków oświetleniowych, rozpoznawania scen, ulepszania zdjęć przy słabym oświetleniu i stosowania ulepszania obrazu w czasie rzeczywistym bezpośrednio na urządzeniu.Asystenci głosowi korzystają również z lokalnego przyspieszenia AI w zakresie rozpoznawania mowy, tłumienia szumów, transkrypcji i przetwarzania języka naturalnego.
Ponieważ te operacje AI działają lokalnie na smartfonie, użytkownicy doświadczają krótszego czasu reakcji, mniejszych opóźnień, większej prywatności i mniejszej zależności od przetwarzania w chmurze.
Jednostki NPU w systemach Edge AI
Systemy Edge AI przetwarzają dane lokalnie w pobliżu źródła, zamiast stale przesyłać informacje do zdalnych serwerów w chmurze.Jednostki NPU są szczególnie ważne w tych środowiskach, ponieważ zapewniają szybkie wnioskowanie AI przy jednoczesnym zachowaniu niskiego zużycia energii i wydajnej pracy w czasie rzeczywistym.
Platformy Edge AI powszechnie wykorzystują jednostki NPU do:
• Wykrywanie obiektów w czasie rzeczywistym
• Lokalne przetwarzanie obrazu
• Analiza czujników
• Monitorowanie predykcyjne
• Inteligentna automatyzacja
• Analityka wideo
Dzięki lokalnemu przetwarzaniu obciążeń AI systemy brzegowe mogą reagować znacznie szybciej, jednocześnie zmniejszając wymagania dotyczące przepustowości i zależność od infrastruktury chmury.
NPU w przemysłowej sztucznej inteligencji i automatyzacji
Systemy przemysłowe coraz częściej wykorzystują jednostki NPU do analizy sztucznej inteligencji w czasie rzeczywistym w systemach produkcyjnych, inspekcji, konserwacji predykcyjnej i zautomatyzowanych systemach sterowania.
Fabryki często wdrażają kamery, czujniki i systemy robotyki, które w sposób ciągły generują dane operacyjne.Jednostki NPU pomagają przetwarzać te informacje lokalnie, aby identyfikować awarie sprzętu, wykrywać wady produkcyjne, monitorować zachowanie maszyn i optymalizować wydajność produkcji przy minimalnym opóźnieniu.
Przemysłowe zastosowania sztucznej inteligencji zwykle obejmują:
• Zautomatyzowane systemy kontroli
• Wykrywanie defektów
• Konserwacja predykcyjna
• Sterowanie robotyką
• Fuzja czujników
• Inteligentne monitorowanie produkcji
Ponieważ te obciążenia wymagają ciągłej pracy i krótkich czasów reakcji, bardzo ważne staje się lokalne przyspieszenie AI z niskimi opóźnieniami.
NPU w robotyce i systemach autonomicznych
Aby bezpiecznie i efektywnie współdziałać ze zmieniającymi się środowiskami, systemy robotyki w dużym stopniu opierają się na wnioskowaniu AI w czasie rzeczywistym.Roboty w trakcie pracy stale przetwarzają dane wejściowe z kamery, dane z czujników, mapy środowiska, informacje o głębokości i śledzenie ruchu.
Jednostki NPU przyspieszają te obciążenia, obsługując obliczenia sieci neuronowej lokalnie, zapewniając mniejsze opóźnienia i krótsze czasy reakcji.Dzięki temu roboty mogą szybciej reagować podczas nawigacji, wykrywania przeszkód, śledzenia obiektów i autonomicznego ruchu.
Systemy autonomiczne, takie jak platformy autonomiczne, również w dużym stopniu opierają się na jednostkach NPU w zakresie:
• Wykrywanie pasa ruchu
• Rozpoznawanie pieszych
• Analiza ruchu
• Przetwarzanie czujnika
• Mapowanie środowiska
• Decyzje nawigacyjne w czasie rzeczywistym
Ponieważ systemy autonomiczne muszą natychmiast reagować na zmieniające się otoczenie, lokalne przetwarzanie sztucznej inteligencji staje się ważne dla bezpiecznego i stabilnego działania.
Jednostki NPU w opiece zdrowotnej i systemach medycznych
Systemy opieki zdrowotnej coraz częściej wykorzystują jednostki NPU do analiz medycznych wspomaganych sztuczną inteligencją, monitorowania pacjentów i przenośnych urządzeń medycznych.
Zadania związane z medyczną sztuczną inteligencją często wymagają ciągłej analizy sygnałów biologicznych, danych obrazowych i systemów monitorowania w czasie rzeczywistym.Jednostki NPU pomagają przyspieszyć te zadania, jednocześnie zmniejszając opóźnienia podczas operacji monitorowania.
Typowe zastosowania w służbie zdrowia obejmują:
• Analiza obrazowania medycznego
• Systemy monitorowania pacjenta
• Przenośne urządzenia diagnostyczne
• Analiza tętna
• Diagnostyka wspomagana sztuczną inteligencją
• Ciągłe monitorowanie stanu zdrowia
Lokalne przyspieszenie AI pomaga również poprawić prywatność, ponieważ wrażliwe dane medyczne mogą pozostać w urządzeniu, zamiast być stale przesyłane do serwerów zewnętrznych.
NPU w inteligentnych domach i urządzeniach IoT
Urządzenia IoT i systemy inteligentnego domu często działają z ograniczoną mocą obliczeniową i rygorystycznymi ograniczeniami energetycznymi, co sprawia, że jednostki NPU są bardzo cenne dla wydajnego lokalnego przetwarzania sztucznej inteligencji.
Urządzenia takie jak inteligentne kamery, inteligentne głośniki, asystenci domowi, systemy bezpieczeństwa i czujniki środowiskowe wykorzystują jednostki NPU do analizowania danych bezpośrednio na urządzeniu, bez nadmiernego polegania na infrastrukturze chmury.
Typowe obciążenia AI IoT obejmują:
• Rozpoznawanie twarzy
• Wykrywanie ruchu
• Wykrywanie obecności człowieka
• Interakcja głosowa
• Rozpoznawanie obiektów
• Inteligentne systemy monitorowania
Lokalne przetwarzanie AI zmniejsza wykorzystanie przepustowości, poprawia szybkość reakcji i pozwala systemom IoT pozostać aktywnymi przez długi czas przy niższym zużyciu energii.
NPU w systemach sieciowych i komunikacyjnych
Nowoczesne systemy sieciowe coraz częściej wykorzystują jednostki NPU do inteligentnego zarządzania komunikacją i analizy ruchu w czasie rzeczywistym.
Infrastruktura komunikacyjna w sposób ciągły przetwarza duże ilości danych sieciowych, aktywności połączeń i zachowań w ruchu.Jednostki NPU pomagają przyspieszyć obciążenia AI związane z alokacją przepustowości, wykrywaniem anomalii, optymalizacją sygnału i zarządzaniem ruchem sieciowym.
Systemy te powszechnie wykorzystują jednostki NPU do:
• Inteligentne ustalanie priorytetów ruchu
• Optymalizacja sygnału
• Wykrywanie anomalii sieci
• Analiza komunikacji
• Zarządzanie przepustowością w czasie rzeczywistym
Przetwarzając te obciążenia lokalnie i wydajnie, systemy sieciowe mogą szybciej reagować na zmieniające się warunki komunikacji.
Dlaczego NPU stają się coraz ważniejsze
Nowoczesne systemy sztucznej inteligencji w coraz większym stopniu wymagają szybkiego wnioskowania lokalnego, responsywności w czasie rzeczywistym, mniejszych opóźnień i efektywnego zużycia energii w wielu różnych środowiskach.Przetwarzanie sztucznej inteligencji wyłącznie w chmurze jest często zbyt wolne, wymagające dużej przepustowości lub niepraktyczne dla systemów, które muszą reagować natychmiast.
Jednostki NPU rozwiązują ten problem, przyspieszając obciążenia sieci neuronowej bezpośrednio na sprzęcie lokalnym.W miarę rozprzestrzeniania się sztucznej inteligencji na smartfony, automatykę przemysłową, robotykę, systemy opieki zdrowotnej, urządzenia IoT, maszyny autonomiczne i platformy przetwarzania brzegowego, jednostki NPU stają się jedną z podstawowych technologii stojących za nowoczesnymi inteligentnymi systemami.
Przyszłe trendy NPU
Technologia NPU wchodzi w okres szybkiej ewolucji w miarę ciągłego zwiększania się obciążeń AI w smartfonach, systemach przemysłowych, robotyce, maszynach autonomicznych, platformach brzegowych AI, infrastrukturze chmurowej i inteligentnych urządzeniach konsumenckich.Nowoczesne modele sztucznej inteligencji stają się coraz większe, bardziej złożone i bardziej wymagające pod względem szybkości przetwarzania, przepustowości pamięci, wydajności cieplnej i zużycia energii.
Wczesny rozwój NPU skupiał się głównie na zwiększaniu wydajności surowej sztucznej inteligencji.Przyszły rozwój będzie wykraczał poza proste skalowanie wydajności i skupiał się bardziej na inteligentnej alokacji obciążenia, wydajnym przepływie danych, adaptacyjnym zachowaniu sprzętu, wnioskowaniu przy niskim poborze mocy i głębszej integracji z szerszymi ekosystemami sztucznej inteligencji.W miarę coraz głębszej integracji sztucznej inteligencji z urządzeniami codziennego użytku i środowiskami przemysłowymi oczekuje się, że jednostki NPU staną się jedną z podstawowych technologii leżących u podstaw inteligentnych systemów komputerowych nowej generacji.
Inteligentniejsze architektury AI
Przyszłe architektury NPU staną się bardziej adaptacyjne, wyspecjalizowane i ściśle zintegrowane z innymi procesorami w nowoczesnych systemach komputerowych.Zamiast działać jako izolowane bloki sprzętowe, jednostki NPU będą ściślej współpracować z procesorami CPU, GPU, procesorami DSP i innymi akceleratorami poprzez systemy pamięci współdzielonej i skoordynowane zarządzanie obciążeniem.
Podczas pracy obciążenia mogą automatycznie przełączać się między procesorami w zależności od warunków termicznych, ograniczeń mocy, złożoności modelu i zapotrzebowania na przetwarzanie w czasie rzeczywistym.Zadania sterowania sekwencyjnego mogą pozostać na procesorze, obciążenia graficzne na GPU, podczas gdy wnioskowanie sieci neuronowej jest dynamicznie przenoszone do NPU.
Przyszłe architektury mogą również dynamicznie reorganizować zasoby sprzętowe podczas wykonywania.Obciążenia AI skupione na rozpoznawaniu obrazów mogą nadawać priorytet sprzętowi tensorowemu i splotowemu, podczas gdy zadania przetwarzania języka mogą przydzielać więcej zasobów na rzecz mechanizmów uwagi i przepustowości pamięci.
Jednocześnie przyszłe jednostki NPU będą w coraz większym stopniu zawierać bloki sprzętowe zoptymalizowane pod kątem określonych obciążeń AI, takie jak:
• Przetwarzanie uwagi transformatora
• Potoki wnioskowania dotyczące wizji
• Rozpoznawanie mowy
• Systemy rekomendacji
• Obciążenia generatywnej sztucznej inteligencji
• Multimodalne przetwarzanie AI
To połączenie dynamicznego zachowania sprzętu i specjalistycznego przyspieszenia AI poprawi przepustowość, ograniczy niepotrzebne obliczenia i zwiększy ogólną wydajność podczas złożonych obciążeń AI.
Energooszczędne i wydajne przetwarzanie AI
Efektywność energetyczna stanie się jednym z najważniejszych priorytetów przyszłego rozwoju NPU, zwłaszcza w obliczu rozszerzenia obciążeń AI na smartfony, urządzenia elektroniczne do noszenia, czujniki przemysłowe i urządzenia brzegowe AI.
Przyszłe jednostki NPU będą nadal rozszerzać obsługę formatów o niskiej precyzji, takich jak INT4, INT8, FP16, BF16 i ultraniskobitowe obliczenia AI.Zamiast stosować tę samą precyzję numeryczną w każdej warstwie sieci neuronowej, przyszłe systemy będą mogły dynamicznie dostosowywać poziomy precyzji w zależności od wrażliwości obciążenia.
Takie podejście zmniejsza:
• Narzut związany z transferem pamięci
• Wymagania dotyczące przechowywania
• Zużycie energii
• Opóźnienie obliczeniowe
jednocześnie zwiększając ogólną przepustowość.
Coraz większe znaczenie będzie mieć także przyspieszenie obliczeń rzadkich.Wiele sieci neuronowych zawiera regiony nieaktywne lub o niskim znaczeniu, które w niewielkim stopniu wpływają na końcową jakość wydruku.Przyszłe jednostki NPU mogą automatycznie wykrywać i omijać te regiony, aby uniknąć marnowania energii na niepotrzebne obliczenia.
Kolejnym ważnym obszarem rozwoju są obliczenia w pamięci.Zamiast ciągłego przesyłania danych sieci neuronowej między pamięcią a sprzętem wykonawczym, przyszłe architektury mogą wykonywać pewne obliczenia tensorowe bezpośrednio w strukturach pamięci.Pojawiające się technologie, takie jak ReRAM, MRAM, pamięć ze zmianą fazy i zaawansowane architektury stosowe 3D mogą znacznie zmniejszyć wąskie gardła pamięci, poprawiając jednocześnie wydajność przepustowości i obniżając zużycie energii.
Inspirowany mózgiem i adaptacyjny sprzęt AI
Obliczenia neuromorficzne stopniowo przechodzą od badań eksperymentalnych do zastosowań praktycznych.Architektury te są inspirowane biologicznymi systemami neuronowymi i przetwarzają informacje inaczej niż tradycyjne procesory sterowane zegarem.
Zamiast ciągłego wykonywania operacji w ustalonych odstępach czasu, systemy neuromorficzne często wykorzystują metody przetwarzania sterowane zdarzeniami, podobne do impulsowych sieci neuronowych.Obliczenia mają miejsce głównie wtedy, gdy pojawiają się znaczące sygnały, co znacznie ogranicza niepotrzebną aktywność wewnątrz procesora.
Przyszłe jednostki NPU mogą obejmować specjalistyczne wsparcie dla:
• Imponujące sieci neuronowe
• Wnioskowanie sterowane zdarzeniami
• Adaptacyjne uczenie się neuronowe
• Ciągła optymalizacja lokalna
Takie podejście może znacznie poprawić efektywność energetyczną robotyki, urządzeń do noszenia, systemów wykrywania środowiska i autonomicznych platform brzegowych sztucznej inteligencji, które wymagają ciągłej pracy przy niskim poborze mocy.
Przyszły sprzęt AI może również dynamicznie dostosowywać zachowanie w oparciu o wzorce interakcji użytkownika i warunki środowiskowe, umożliwiając urządzeniom lepszą personalizację i lokalne uczenie się bez nadmiernego polegania na systemach szkoleniowych w chmurze.
Edge AI i lokalne duże modele
Przyszłe jednostki NPU radykalnie poszerzą możliwości lokalnej sztucznej inteligencji na brzegu sieci.Zamiast w dużym stopniu polegać na serwerach w chmurze, więcej urządzeń będzie przetwarzać obciążenia AI bezpośrednio na sprzęcie lokalnym, zapewniając mniejsze opóźnienia, krótszy czas reakcji i lepszą ochronę prywatności.
Systemy Edge AI będą w coraz większym stopniu wspierać:
• Ciągłe wnioskowanie lokalne
• Lekkie szkolenie na urządzeniu
• Rozproszona współpraca AI
• Inteligentne monitorowanie w czasie rzeczywistym
• Systemy czujnikowe o bardzo niskim poborze mocy
Jednocześnie duże modele językowe i zaawansowane generatywne systemy sztucznej inteligencji stopniowo zmierzają w kierunku lokalnego wdrażania na smartfonach, laptopach, platformach robotyki i sprzęcie brzegowym.
Przyszłe jednostki NPU zapewnią przyspieszenie dla obciążeń takich jak:
• Konwersacyjna sztuczna inteligencja
• Tłumaczenie w czasie rzeczywistym
• Inteligentne podsumowanie
• Asystenci AI offline
• Rozumowanie uwzględniające kontekst
• Generacyjna sztuczna inteligencja na urządzeniu
Multimodalna sztuczna inteligencja również stanie się znacznie bardziej powszechna.Przyszłe systemy będą przetwarzać tekst, wideo, dźwięk, dane z czujników, mapowanie środowiska i interakcje przestrzenne jednocześnie w czasie rzeczywistym.Stanie się to szczególnie istotne w robotyce, systemach autonomicznych, platformach AR/VR, automatyce przemysłowej i inteligentnych urządzeniach brzegowych.
Innowacje w zakresie półprzewodników i sprzętu
Postępy w produkcji półprzewodników będą w dalszym ciągu napędzać znaczną poprawę możliwości NPU.Mniejsze węzły procesowe pozwalają zmieścić więcej tranzystorów w kompaktowych chipach, zmniejszając jednocześnie moc przełączania i poprawiając gęstość obliczeniową.
Przyszły rozwój NPU będzie w coraz większym stopniu opierał się na:
• Architektury chipletów
• Układanie 3D
• Zaawansowane technologie pakowania
• Systemy połączeń wzajemnych o dużej przepustowości
• Modularne projekty akceleratorów AI
Zamiast budować jedną bardzo dużą matrycę procesora, przyszłe systemy będą mogły łączyć wiele wyspecjalizowanych modułów chipowych w ściśle zintegrowanych pakietach.Oddzielne chiplety mogą niezależnie obsługiwać akcelerację tensorową, zarządzanie pamięcią, kontrolę komunikacji lub planowanie AI, zachowując jednocześnie wyjątkowo wysoką przepustowość wewnętrzną.
Naukowcy badają także zaawansowane materiały półprzewodnikowe, takie jak grafen, nanorurki węglowe i półprzewodniki złożone, które mogą jeszcze bardziej poprawić szybkość przełączania, sprawność cieplną i wydajność energetyczną przyszłego sprzętu AI.
Bezpieczeństwo AI i rozwój ekosystemu
W miarę jak coraz więcej zadań związanych ze sztuczną inteligencją będzie przenoszonych bezpośrednio na sprzęt lokalny, bezpieczeństwo sztucznej inteligencji i rozwój ekosystemów będą zyskiwać na znaczeniu.
Przyszłe jednostki NPU mogą obejmować dedykowaną akcelerację sprzętową dla:
• Uczenie się stowarzyszone
• Szyfrowane wykonanie AI
• Bezpieczne przechowywanie modelu
• Różnicowa prywatność
• Chronione potoki wnioskowania
Staje się to szczególnie ważne w systemach opieki zdrowotnej, infrastrukturze przemysłowej, systemach autonomicznych, platformach finansowych i osobistych asystentach AI, gdzie wrażliwe informacje muszą pozostać chronione podczas lokalnego przetwarzania AI.
Przyszłe ekosystemy NPU również staną się bardziej ustandaryzowane i przyjazne dla programistów.Kompilatory AI, środowiska debugowania, platformy optymalizacyjne i narzędzia do wdrażania będą nadal udoskonalane w miarę zwiększania się specjalizacji architektur sprzętowych.
Przyszłe systemy oprogramowania AI mogą automatycznie:
• Optymalizuj ścieżki wykonania tensora
• Zmień alokację pamięci
• Dynamicznie dostosowuj precyzję
• Wygeneruj kod akceleracji specyficzny dla sprzętu
• Poprawa kompatybilności między platformami
Standaryzowane interfejsy i szersza kompatybilność ekosystemów pomogą zmniejszyć fragmentację między dostawcami sprzętu, jednocześnie poprawiając przenośność, skalowalność i efektywność rozwoju w branży sztucznej inteligencji.
Wniosek
Jednostki NPU stają się niezbędne w nowoczesnym informatyce, ponieważ umożliwiają lokalne, szybkie i wydajne wykonywanie zadań AI, bez nadmiernego uzależnienia od przetwarzania w chmurze.Ich zoptymalizowana architektura zmniejsza opóźnienia, zużycie energii, przemieszczanie pamięci i wytwarzanie ciepła, co czyni je cennymi w smartfonach, robotyce, urządzeniach opieki zdrowotnej, automatyce przemysłowej, inteligentnych domach, systemach autonomicznych i brzegowych platformach AI.W miarę jak modele sztucznej inteligencji stają się większe i bardziej złożone, przyszłe jednostki NPU będą nadal udoskonalane dzięki inteligentniejszym architekturom, przetwarzaniu o niskiej precyzji, przetwarzaniu w pamięci, lokalnej obsłudze dużych modeli, zaawansowanej konstrukcji półprzewodników i silniejszym funkcjom bezpieczeństwa AI.
Często zadawane pytania [FAQ]
1. Dlaczego jednostki NPU są bardziej wydajne niż procesory w przypadku obciążeń sieci neuronowej?
Jednostki NPU są bardziej wydajne, ponieważ ich sprzęt został zaprojektowany specjalnie do obliczeń AI, a nie do przetwarzania ogólnego.Procesor obsługuje sekwencyjnie wiele różnych zadań systemowych, podczas gdy NPU koncentruje się głównie na operacjach tensorowych, mnożeniu macierzy, splocie i równoległym przetwarzaniu sieci neuronowej.Dzięki temu jednostki NPU mogą szybciej wnioskować o sztucznej inteligencji, zużywając przy tym mniej energii i generując mniej ciepła.
2. W jaki sposób przetwarzanie równoległe poprawia wydajność NPU podczas wnioskowania AI?
Jednostki NPU dzielą obciążenia AI na wiele mniejszych operacji, które działają jednocześnie na wielu jednostkach obliczeniowych.Zamiast czekać na zakończenie jednej instrukcji przed uruchomieniem kolejnej, duże ilości danych sieci neuronowej przepływają równolegle przez procesor.Znacząco poprawia to przepustowość i zmniejsza opóźnienia podczas obciążeń, takich jak rozpoznawanie obrazu, przetwarzanie mowy i wykrywanie obiektów w czasie rzeczywistym.
3. Dlaczego obliczenia o niskiej precyzji są ważne w nowoczesnych jednostkach NPU?
Wiele modeli sztucznej inteligencji nie wymaga niezwykle dużej precyzji numerycznej, aby uzyskać dokładne wyniki.Jednostki NPU korzystają z formatów takich jak INT8 i FP16, aby zmniejszyć zużycie pamięci i obciążenie obliczeniowe.Przetwarzanie o niższej precyzji umożliwia wykonanie większej liczby operacji w krótszym czasie, przy jednoczesnej poprawie efektywności energetycznej i utrzymaniu wysokiej wydajności wnioskowania AI.
4. W jaki sposób jednostki NPU zmniejszają wąskie gardła w transferze pamięci w porównaniu z procesorami graficznymi?
Jednostki NPU umieszczają pamięć i sprzęt obliczeniowy bliżej siebie w architekturze procesora.Zamiast wielokrotnie przesyłać duże ilości danych tensorowych pomiędzy pamięcią zewnętrzną a rdzeniami przetwarzającymi, wiele operacji pośrednich pozostaje w pobliżu jednostek wykonawczych.Skraca to ścieżki danych, zmniejsza wykorzystanie przepustowości, zmniejsza opóźnienia i poprawia ogólną efektywność energetyczną.
5. Dlaczego NPU stają się przydatne w smartfonach i urządzeniach brzegowych AI?
Nowoczesne urządzenia wymagają szybkiego lokalnego przetwarzania AI przy niskim zużyciu energii i minimalnych opóźnieniach.Jednostki NPU umożliwiają smartfonom i systemom brzegowym wykonywanie zadań AI, takich jak rozpoznawanie twarzy, fotografowanie AI, interakcja głosowa i wykrywanie obiektów bezpośrednio na urządzeniu, bez dużej zależności od serwerów w chmurze.Poprawia to responsywność, prywatność i wydajność baterii.
6. W jaki sposób jednostki MAC przyczyniają się do akceleracji NPU?
Jednostki mnożenia i akumulowania (MAC) obsługują powtarzające się operacje mnożenia i dodawania stosowane w sieciach neuronowych.Nowoczesne jednostki NPU zawierają setki lub tysiące jednostek MAC pracujących jednocześnie, dzięki czemu duże obciążenia AI mogą być przetwarzane znacznie szybciej niż w przypadku tradycyjnych procesorów sekwencyjnych.
7. Dlaczego nowoczesne systemy AI wykorzystują zarówno procesory graficzne, jak i NPU, zamiast polegać na jednym typie procesora?
Procesory graficzne i NPU są zoptymalizowane pod kątem różnych obciążeń.Procesory graficzne przodują w szkoleniu AI na dużą skalę, renderowaniu grafiki i wysokowydajnych obliczeniach równoległych, podczas gdy jednostki NPU są zoptymalizowane pod kątem wnioskowania AI o niskim poborze mocy i lokalnego przetwarzania w czasie rzeczywistym.Użycie obu procesorów razem pozwala systemom zrównoważyć elastyczność, wydajność i efektywność energetyczną.
8. W jaki sposób jednostki NPU usprawniają przetwarzanie AI w czasie rzeczywistym w robotyce i systemach autonomicznych?
Robotyka i systemy autonomiczne w sposób ciągły przetwarzają dane wejściowe z kamery, mapy środowiska, dane z czujników i analizę ruchu.Jednostki NPU przyspieszają te obciążenia lokalnie przy niskim opóźnieniu, umożliwiając systemom szybką reakcję podczas nawigacji, wykrywania przeszkód, rozpoznawania pieszych i podejmowania decyzji w czasie rzeczywistym.
9. Dlaczego sztuczna inteligencja na urządzeniu staje się coraz ważniejsza dla przyszłego rozwoju NPU?
Sztuczna inteligencja na urządzeniu zmniejsza zależność od przetwarzania w chmurze, umożliwiając działanie modeli sztucznej inteligencji bezpośrednio na sprzęcie lokalnym.Poprawia to prywatność, zmniejsza wykorzystanie przepustowości sieci i umożliwia szybsze reakcje w czasie rzeczywistym.Oczekuje się, że przyszłe jednostki NPU będą obsługiwać większe lokalne modele sztucznej inteligencji, multimodalne przetwarzanie sztucznej inteligencji i zaawansowane obciążenia generatywnej sztucznej inteligencji bezpośrednio w urządzeniach konsumenckich i przemysłowych.
10. W jaki sposób przyszłe architektury NPU mogą zmienić wydajność sprzętu AI?
Przyszłe jednostki NPU będą prawdopodobnie wykorzystywać inteligentniejszą alokację obciążenia, przetwarzanie rzadkie, przetwarzanie w pamięci, architekturę chipletów i adaptacyjną precyzyjną kontrolę w celu poprawy wydajności.Technologie te mają na celu ograniczenie niepotrzebnych obliczeń, zmniejszenie zużycia energii i zwiększenie przepustowości przy jednoczesnej obsłudze większych i bardziej zaawansowanych modeli sztucznej inteligencji w urządzeniach brzegowych, robotyce, systemach przemysłowych i inteligentnej elektronice użytkowej.
Powiązany blog
-
Ile zer na milion, miliard, bilion?
![Ile zer na milion, miliard, bilion?]()
2024/07/29
Million reprezentuje 106, łatwo chwytana liczba w porównaniu do przedmiotów codziennych lub rocznych pensji. Miliard, równoważny 109, zaczyna roz... -
IRLZ44N MOSFET Arkusz, obwód, równoważny, pinout
![IRLZ44N MOSFET Arkusz, obwód, równoważny, pinout]()
2024/08/28
IRLZ44N to szeroko stosowany Mosfet Power N-Kannel.Znany z doskonałych możliwości przełączania, jest bardzo odpowiedni do wielu zastosowań, szcz... -
Temperatura akumulatora zbyt niska, ładowanie zatrzymało się.Jak to naprawić?
![Temperatura akumulatora zbyt niska, ładowanie zatrzymało się.Jak to naprawić?]()
2024/10/6
Problemy z ładowaniem baterii telefonu komórkowego są powszechne, ale można je skutecznie zarządzać.Temperatura odgrywa dużą rolę w wydajnoś... -
BC547 Tranzystor Kompleksowy przewodnik
![BC547 Tranzystor Kompleksowy przewodnik]()
2024/07/4
Tranzystor BC547 jest powszechnie stosowany w różnych zastosowaniach elektronicznych, od podstawowych wzmacniaczy sygnałowych po złożone obwody o... -
Kompleksowy przewodnik po SCR (prostownik kontrolowany krzem)
![Kompleksowy przewodnik po SCR (prostownik kontrolowany krzem)]()
2024/04/22
Kontroli prostownicy (SCR) lub Thyristors odgrywają kluczową rolę w technologii elektroniki energetycznej ze względu na ich wydajność i niezawod... -
LR621, SR621SW, 364, AG1 Equivivalents i zamienniki
![LR621, SR621SW, 364, AG1 Equivivalents i zamienniki]()
2024/07/15
Baterie przycisków LR621 i SR621SW są powszechne w kompaktowych urządzeniach elektronicznych, takich jak zegarki, małe zabawki, kalkulatory i zdal... -
Podstawy obwodów OP-AMP
![Podstawy obwodów OP-AMP]()
2023/12/28
W skomplikowanym świecie elektroniki podróż do jej tajemnic niezmiennie prowadzi nas do kalejdoskopu komponentów obwodów, zarówno wykwintnych, j... -
Porównanie różnic i zastosowań NMOS i PMOS
![Porównanie różnic i zastosowań NMOS i PMOS]()
2024/11/15
Zrozumienie różnic między tranzystorami NMOS i PMO jest ważne w projektowaniu wydajnych obwodów.NMOS (NMOS-semiconductor) i PMOS (typ p-tlenku-tl... -
Kompletny przewodnik po multiplekserach i ich rola w systemach cyfrowych
![Kompletny przewodnik po multiplekserach i ich rola w systemach cyfrowych]()
2025/09/20
Multipleksery są komponentami w systemach cyfrowych, zaprojektowanych do kierowania wieloma sygnałami wejściowymi do pojedynczej linii wyjściowej ... -
Co oznaczają STD, AGM i GEL na ładowarce
![Co oznaczają STD, AGM i GEL na ładowarce]()
2024/07/10
Tradycyjne ładowarki akumulatorów ołowiowych są znane ze swojej prostoty i niezawodności.Od lat skutecznie służą swoim celu, głównie ze wzgl...










Gorące części
- FCX558TA
- TIBPAL16R8-15CFN
- TMS320DM642AGDK6
- PI74LPT16245CAEX
- C0603X5R1E221K030BA
- SE16AWL-LF
- 7MBR100U2P060
- KS4H2U1C32CFP
- LT1084CP
- TL16C452FNRG4
- HD64F38024RWV
- 2MBI1400VXB-120P-50
- PIC16F722A-I/SS
- FLT007A0Z
- L6574D013TR
- ATSAM4S2BA-MU
- STM32F301K8U6TR
- MCZ33972TEW/R2
- TMP87CH40F
- V48C15H150AL2
- T495V227M010ASE150
- TC6416AFG
- CY7C245A-15JI
- MSP430F5510IRGZR
- LR350J04/E2
- CY7B994V-5BBCT
- LTC2865IMSE#TRPBF
- 6MBI300V-120-50
- LC78663NRW-UST-E
- ISL6295CV
- UPD780102MC-039-5A4-E1
- EL7566DRE
- UCC27424DGNRG4
- CL10C360JB8NNNC
- PEB3332ELV1.4
- STM8S207S6T6C
- PCB80C31BH-3-16WP
- DMC6003B03
- CAT28LV64NI-25
- 06032U1R5CAT2A
- BQ24103RHLR
- TLK2208BGPV
- T491D476K025ZTZV10
- PFE1000FA-48
- T491B335M016ZTZ001
- XC2S300E-7FGG456C
- GN07001S02MC
- MT41J128M16JT-125K
- LPC1765FBD100K
- ACS772LCB-100B-PFF-T