- polski
-
EnglishDeutschItaliaFrançais한국의русскийSvenskaNederlandespañolPortuguêspolski繁体中文SuomiGaeilgeSlovenskáSlovenijaČeštinaMelayuMagyarországHrvatskaDanskromânescIndonesiaΕλλάδαБългарски езикGalegolietuviųMaoriRepublika e ShqipërisëالعربيةአማርኛAzərbaycanEesti VabariikEuskeraБеларусьLëtzebuergeschAyitiAfrikaansBosnaíslenskaCambodiaမြန်မာМонголулсМакедонскиmalaɡasʲພາສາລາວKurdîსაქართველოIsiXhosaفارسیisiZuluPilipinoසිංහලTürk diliTiếng ViệtहिंदीТоҷикӣاردوภาษาไทยO'zbekKongeriketবাংলা ভাষারChicheŵaSamoa日本語SesothoCрпскиKiswahiliУкраїнаनेपालीעִבְרִיתپښتوКыргыз тилиҚазақшаCatalàCorsaLatviešuHausaગુજરાતીಕನ್ನಡkannaḍaमराठी
Programowanie FPGA Xilinx i przepływ projektowania w Vivado wyjaśnione
Katalog

Zgłębianie samouczków FPGA Xilinx
Praca z FPGA może na początku wydawać się mentalnie trudniejsza niż z oprogramowaniem, częściowo dlatego, że celem nie jest wykonywanie instrukcji, lecz opisywanie struktur sprzętowych, które działają równocześnie. Zaczynasz myśleć o współbieżności, zasadach zegara, zachowaniu resetu i tym, czy raporty czasowe zgadzają się z tym, co uważasz, że zbudowałeś. Kiedy ludzie zniechęcają się na początku, często nie dlatego, że brakuje im wysiłku, ale dlatego, że zbyt wiele ruchomych części zmienia się między próbami, a przyczyna niepowodzenia staje się irytująco nieuchwytna.
Stabilny sposób postępu polega na powtarzaniu tego samego przepływu pracy, aż stanie się na tyle znajomy, że błędy będą się wyróżniać. Trzymaj jedną dobrze wspieraną płytę Xilinx na swoim biurku, zacznij od małego projektu HDL, symuluj go, aż przebiegi będą miały sens, przeprowadź syntezę i implementację w Vivado, zaprogramuj urządzenie, a następnie potwierdź zachowanie na rzeczywistych pinach. Chociaż ten proces może wydawać się powtarzalny, pomaga zredukować niepewność co do tego, czy problem jest spowodowany kodem projektu, ograniczeniami czy konfiguracją płyty, co sprawia, że debugowanie staje się bardziej efektywne.
W codziennym uczeniu, stroma część krzywej zwykle koncentruje się wokół kilku umiejętności, które wzmacniają się nawzajem: korzystanie z przepływu Vivado w sposób zdyscyplinowany, pisanie syntezowalnego Veriloga, który odzwierciedla oczekiwania i debugowanie nieuchronnych luk między symulacją a fizyczną płytą metodą, której ufasz. Jeśli potraktujesz każdą budowę jako kontrolowany eksperyment, zmień jedną zmienną, obserwuj efekt i zapisz, co widziałeś, zauważysz, że spędzasz mniej czasu na zgadywaniu, a więcej na kształtowaniu niezawodnych instynktów.
Użyj projektu Vivado w sposób, który pozostaje stabilny w czasie
Vivado zachowuje się mniej jak prosty przycisk kompilacji, a bardziej jak pipeline, który przekształca RTL w zaprojektowany i poprowadzony układ, który musi funkcjonować w ramach elektrycznych i czasowych rzeczywistości płyty. Wielu początkujących odkrywa, czasami w trudny sposób, że wiele kwestii poprawności leży poza HDL: ograniczenia, definicje zegarów, standardy I/O i ustawienia narzędzi mogą cicho decydować, czy sprzęt działa zgodnie z obietnicami symulacji.
Czysty przepływ zaczyna się od utrzymania skromnej i powtarzalnej konfiguracji projektu, abyś mógł odróżnić, kiedy rzeczywiście poprawiłeś projekt od momentu, gdy przypadkowo zmieniłeś środowisko.
Wybierz jedną wspieraną płytę i trzymaj się jej wystarczająco długo, aby zbudować intuicję, którą możesz ponownie wykorzystać. Płyty z solidną dokumentacją i wzorcami projektowymi tendencją do obniżania tła lęku, ponieważ możesz sprawdzić swoje rozmieszczenie pinów, założenia dotyczące zegarów i zasilania bez poszukiwania nieoficjalnych postów na forach.
Zacznij od górnego modułu, który szybko produkuje widoczny wynik. To natychmiastowe sprzężenie zwrotne pomaga potwierdzić, że zegar działa, piny są mapowane prawidłowo, a strumienie bitowe są generowane tak, jak myślisz, że są.
Przykłady obserwowalnego zachowania na najwyższym poziomie:
• Mrugająca dioda LED
• Echo UART
• Licznik prowadzący GPIO
Praktycznym nawykiem jest ustandaryzowanie małego szablonu najwyższego poziomu na wczesnym etapie. Na przykład, trzymaj jedno wejście zegara, jedno podejście do resetowania, które rozumiesz, oraz mały, spójny pakiet GPIO. Gdy konstrukcja pozostaje taka sama z projektu na projekt, możesz skupić swoją uwagę na nowej logice, a nie na ponownym wyprowadzaniu podstaw za każdym razem, co może wydawać się żmudne i zaskakująco podatne na błędy.
Ograniczenia są zasadniczą częścią projektowania FPGA, a nie ostatnim krokiem dostosowawczym. Wiele wczesnych problemów sprzętowych występuje nawet wtedy, gdy projekt RTL jest poprawny, ponieważ brakuje lub są błędne ograniczenia zegara, piny są niewłaściwie przypisane, lub standardy I/O nie odpowiadają rzeczywistym wymaganiom płytki.
Konkretna procedura robocza, która utrzymuje cię w ryzach, polega na definiowaniu zegarów w XDC, mapowaniu portów za pomocą nadrzędnego XDC dostawcy jako odniesienia, a następnie weryfikacji standardów I/O w odniesieniu do schematu płytki. Ten proces może wydawać się na początku nieco biurokratyczny, ale zazwyczaj zastępuje niejasne podejrzenie rzeczowymi faktami.
Zamknięcie czasowe nie jest również zarezerwowane dla szybkich projektów. Nawet logika, która wygląda wolno na papierze, może działać źle, jeśli narzędzie wnioskuje o niezamierzonych relacjach zegarowych lub jeśli sygnały asynchroniczne są traktowane zbyt swobodnie. Osiągnięcie komfortu w czytaniu raportów czasowych na wczesnym etapie może zmniejszyć to niespokojne uczucie „mam nadzieję, że to w porządku”, gdy projekty stają się większe.
Vivado ciągle mówi ci, co myśli o twoim projekcie; bolesna część polega na tym, że łatwo jest kliknąć przez ostrzeżenia, a następnie spędzić godziny na debugowaniu problemu, który został już opisany na konsoli. Z czasem osoby, które poruszają się szybciej, często są tymi, które budują spokojny nawyk sprawdzania raportów po każdym uruchomieniu, nawet gdy spodziewają się, że wszystko będzie w porządku.
Po każdym uruchomieniu syntezowania/implementacji trzymaj te kategorie raportów razem na własnej liście kontrolnej:
• Status czasowy i ścieżki krytyczne
• Wykorzystanie zasobów (LUT/FF/BRAM/DSP) w porównaniu do oczekiwań
• Wyniki wnioskowania (dla RAM-ów, bloków DSP i innych zamierzonych struktur)
Kiedy ostrzeżenie jest obecne od pierwszej budowy, często nadal pojawia się w najdziwniejszych awariach później. Produktywna postawa polega na przyjęciu, że ostrzeżenia zasługują na uwagę, dopóki nie możesz wyjaśnić, w prostych terminach inżynieryjnych, dlaczego są nieszkodliwe dla twojego konkretnego projektu.
Napisz syntezowalny Verilog, który czysto mapuje się na sprzęt FPGA
Praca z HDL jest bliższa projektowaniu obwodów niż rozwojowi aplikacji, a ta zmiana może być emocjonalnie wstrząsająca: możesz napisać ważny Verilog, który pięknie symuluje, ale syntetyzuje się w coś wolniejszego, większego lub po prostu różniącego się od twojej wizji. Celem jest opisanie struktur, które FPGA może wdrożyć w sposób przewidywalny: przerzutników, logiki LUT, BRAM-u i bloków DSP, aby zachowanie i czas były zgodne z twoim zamiarem.
Kiedy mapowanie jest przewidywalne, debugowanie wydaje się mniej jak kłócenie się z narzędziem, a bardziej jak udoskonalanie projektu.
Komfortowa baza dla wielu początkujących to pojedyncza domena zegarowa z prostą logiką synchroniczną. Użyj bloków always z zegarem do stanów sekwencyjnych i przypisania ciągłego (lub prawidłowo napisanych bloków kombinacyjnych) do ścieżek kombinacyjnych. Tworzenie logiki „podobnej do zegara” w tkaninie może działać w niszowych przypadkach, ale tendencja do zapraszania ryzyk związanych z domeną zegara może wystąpić, chyba że już rozumiesz przesłanianie zegara, trasowanie i konsekwencje czasowe.
Zachowanie resetu to kolejna sytuacja, w której małe wybory mogą tworzyć zaskakująco niespójne wyniki na płytce. Asynchroniczne resetowanie może być przydatne, jednak może także prowadzić do niebezpieczeństw deassertion lub wrażliwości na różnice w zasilaniu na poziomie płytki. Wiele projektów FPGA wykorzystuje w pełni synchroniczne resetowanie lub asynchroniczne ustawianie z synchronicznym zwolnieniem, ponieważ takie podejścia pomagają zmniejszyć niespójne zachowanie przy uruchamianiu podczas testów uruchamiania.
Logika FPGA naturalnie zmierza w kierunku potoków i równoległych struktur. Powszechnym rozczarowaniem dla początkujących jest oczekiwanie wykonania krok po kroku jak w oprogramowaniu, a następnie odczuwanie dezorientacji, gdy wszystko odbywa się jednocześnie. Bardziej użyteczny punkt widzenia to zdecydowanie, co cię interesuje w danym bloku i następnie projektowanie wyraźnie w celu osiągnięcia tego rezultatu.
Jednolinijkowy punkt widzenia na wydajność i mapowanie:
• Przepustowość (elementy na zegar)
• Opóźnienie (cykle od wejścia do wyjścia)
• Preferencja mapowania zasobów (LUT w porównaniu z BRAM w porównaniu z DSP)
Na przykład, mnożenie-suma może czysto wnioskować o fragmentach DSP, ale drobne zmiany w stylu kodowania mogą skłonić narzędzie do kierowania w stronę arytmetyki opartej na LUT. Kiedy wykorzystanie cię zaskakuje, często warto na chwilę się zatrzymać i zadać nieco niewygodne pytanie: czy faktycznie opisałeś strukturę sprzętową, którą zamierzałeś, czy opisałeś coś funkcjonalnie równoważnego, co kosztuje więcej zasobów?
Symulacja chętnie akceptuje konstrukcje, które rzeczywisty sprzęt nie może wdrożyć w sposób, w jaki możesz sobie to wyobrazić. Utrzymanie wyraźnej granicy syntezowalnej zmniejsza fałszywe poczucie pewności i sprawia, że wyniki symulacji są bardziej przenośne na płytkę.
Wspólne wzorce do zachowania w grupie na jednej linii jako szybki przypomnienie:
• Unikaj opóźnień (#) w logice syntetyzowalnej
• Nie polegaj na inicjalizacji, chyba że potwierdziłeś zachowanie urządzenia/narzędzia
• Uważaj na niezamierzone latch'e z niekompletnych przypisów kombinacyjnych
• Używaj odpowiednich synchronizatorów do przejść między domenami zegarowymi
Nawyk, który często przynosi korzyści, to pisanie małych, samosprawdzających się testbenches, które weryfikują założenia, które masz emocjonalną pokusę zbagatelizować: zachowanie resetu, przepełnienie licznika, protokoły uzgadniania i warunki brzegowe. Kiedy projekty rosną, te testy stają się mniej jak dodatkowa praca, a bardziej jak coś, co powstrzymuje cię przed wątpliwościami w każdej kwestii.
Debuguj systematycznie za pomocą symulacji i widoczności na chipie (ILA)
Nawet doskonała symulacja nie gwarantuje poprawnego zachowania płytki. Prawdziwy sprzęt wprowadza drgania zegara, opóźnienia I/O, nieznane stany początkowe i asynchroniczne wejścia, które nie pasują grzecznie do krawędzi zegara. Najszybsi debuggery zazwyczaj nie są tymi, którzy wprowadzają losowe edycje, to ci, którzy zawężają problem przez strukturalną obserwację i mogą wyjaśnić, jakie dowody zmieniły ich zdanie.
Silny testbench sprawdza zachowanie przez wiele cykli i nie unika niewygodnych scenariuszy. Jeśli modelujesz realistyczne bodźce, symulacja staje się miejscem, w którym budujesz pewność, a nie tylko miejscem, w którym obserwujesz, jak sygnał zmienia stan i masz nadzieję, że to coś znaczy.
Realistyczne bodźce, które tendencją do ujawniania delikatnej logiki:
• Odpryski przycisków
• Błędy w ramce UART
• Backpressure w interfejsach strumieniowych
• Sekwencje resetu z niezgrabnym czasowaniem
Pomaga również podzielić błędy na dwa kosze, aby nie gonić za niewłaściwym rodzajem poprawek:
• Błędy funkcjonalne: logika RTL jest błędna
• Błędy integracji: RTL jest poprawny, ale zegary/resetowanie/ograniczenia/założenia I/O są błędne
Symulacja doskonale radzi sobie z wyłapywaniem błędów funkcjonalnych; testowanie płytki ujawnia błędy integracji, w które nie chciałeś uwierzyć, że są możliwe.
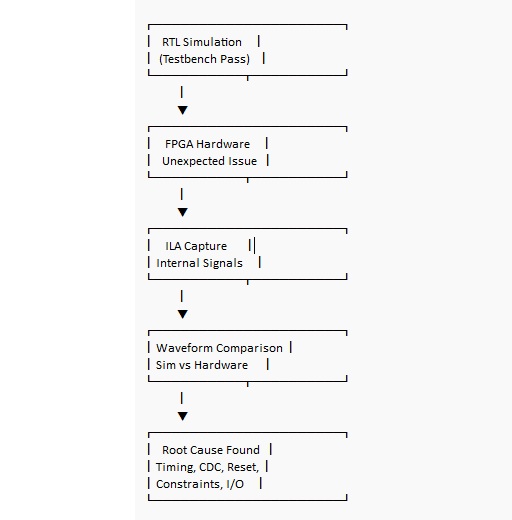
Gdy zachowanie sprzętu kłóci się z twoim testbenchem, Zintegrowany Analizator Logiki (ILA) jest często najprostszym sposobem na zastąpienie spekulacji śledzeniem, które możesz zbadać. Zbadaj sygnały, które reprezentują decyzje i granice wewnątrz projektu, a następnie zarejestruj moment, w którym rzeczy się rozdzielają i porównaj to z oczekiwaną falą symulacyjną.
Sygnały, które mają tendencję do bycia wartościowymi sondami:
• Kodowania stanu FSM
• prawidłowe/gotowe uzgadniania
• flagi FIFO pełne/puste
• wyjścia synchronizatora resetu
Praktyczny workflow polega na rozpoczęciu od mniejszej liczby sond i szerszego okna przechwytywania. Gdy dowiesz się, gdzie znajduje się awaria, możesz zaostrzyć wyzwalacz i dodać szczegóły. Nadmierne instrumentowanie może zmniejszyć margines czasowy i skomplikować budowy, więc zazwyczaj lepiej jest traktować wstawienie ILA jako krok skoncentrowany na pomiarach, a nie jako coś, co trzymasz na wszelki wypadek.
Niektóre z najbardziej edukacyjnych niepowodzeń zdarzają się, gdy symulacja wygląda bezbłędnie, a płytka jest niestabilna. Ta rozbieżność może być zniechęcająca, ale to także miejsce, gdzie intuicja FPGA staje się ostrzejsza, ponieważ poprawka zazwyczaj dotyczy zegarów, ograniczeń lub higieny sygnału, a nie algorytmu.
Powszechne przyczyny rozbieżności symulacji/płytki:
• Brak lub błędne ograniczenia zegarowe
• Metastabilność z niesynchronizowanych wejść
• Zmienność czasowa zwolnienia resetu w całym chipie
• Problemy z CDC między wieloma domenami zegarowymi
• Różnice w warunkach początkowych
Perspektywa, która przyspiesza naukę, to traktowanie czasowania i obserwowalności jako właściwości, które umyślnie wprowadzasz do projektu. Gdy twoje małe projekty wyraźnie definiują zegary, ograniczają I/O, synchronizują przejścia i ujawniają sygnały wewnętrzne do pomiaru, spędzasz mniej czasu na nadziei, że to działa i więcej czasu na wprowadzanie kontrolowanych, wyjaśnialnych ulepszeń. Takie myślenie naturalnie się rozwija od migającej diody LED do większych potoków, interfejsów i systemów wbudowanych na tym samym urządzeniu.
Xilinx (AMD) vs. Altera (Intel) FPG
Xilinx (AMD) i Intel (Altera) obie dostarczają rodziny FPGA, które wyglądają porównywalnie na papierze, i łatwo jest czuć się pewnie po szybkim przeglądzie karty danych. Nastrój zazwyczaj zmienia się później, gdy codzienne realia inżynieryjne zaczynają decydować o tempie: zachowanie narzędzi na twoim dokładnym urządzeniu i stopniu prędkości, czy IP, które zakładałeś, że możesz użyć, jest na pewno licencjonowane w twojej organizacji, czy projekt odniesienia rzeczywiście odpowiada twoim zegarom i resetom, oraz czy zamknięcie czasowe pozostaje stabilne, gdy projekt staje się gotowy do produkcji.
Proces selekcji trzyma się lepiej, gdy traktujesz FPGA jako system dostarczania, urządzenie + narzędzia + IP + płytki + dokumentacja + długoterminowa utrzymywaność, ponieważ to tam zespoły zyskują impet (i sen) lub gromadzą cichą nerwowość w harmonogramie.
| Funkcja |
Xilinx (AMD) |
Intel (Altera) |
| Pozycja na rynku |
Historycznie lider rynku, znany z szerokiego portfolio produktów i bycia pierwszym na rynku z nowymi technologiami. |
Silny konkurent, szczególnie mocny w zastosowaniach centrum danych i sieciowych, wykorzystując umiejętności produkcyjne Intela. |
| Architektura rdzenia |
Logika oparta głównie na 6-wejściowych tablicach poszukiwania (LUT), oferujących wysoką granularność i elastyczność. |
Używa modułów logicznych adaptacyjnych (ALM), które są bardziej złożone i mogą być konfigurowane jako większe LUT, co potencjalnie zwiększa gęstość logiki dla niektórych projektów. |
| Pakiet oprogramowania |
Vivado Design Suite i Vitis Unified Software Platform. Często chwalony za przyjazny interfejs dla doświadczonych programistów. |
Quartus Prime Design Suite. Niektórzy użytkownicy uważają, że jego GUI jest bardziej intuicyjne dla początkujących, a w niektórych scenariuszach jest znane z szybszych czasów kompilacji. |
| Rodziny wyższej klasy |
Versal ACAPs (Adaptive Compute Acceleration Platforms) łączące silniki skalarne, adaptacyjne i inteligentne. |
FPGAs Agilex, znane z wysokiej wydajności i efektywności energetycznej, z niektórymi benchmarkami pokazującymi przewagę wydajności na wat. |
| Skupienie na ekosystemie |
Silne skupienie na integracji procesora i FPGA, co widać w rodzinie Zynq. Popularne w rozwoju aplikacji. |
Doskonałe do projektów System-on-Chip i aplikacji przemysłowych, z silnym portfolio własności intelektualnej dla sieci i RF. |
Zdefiniuj selekcję za pomocą weryfikowalnych ograniczeń, a nie oczekiwań marki
Rozpocznij od wymagań, które możesz testować wcześnie, a nie od wrażeń z wcześniejszych projektów. Celem jest zmniejszenie „niespodzianek w 10. tygodniu”, co jest miejscem, gdzie frustracja i poprawki tendencja się kumuluje.
Lista kontrolna ograniczeń:
• Zasoby logiki: LUT/ALM, rejestry, dostępność trasowania i przewidywany sufit wykorzystania
• Zasoby DSP: liczba bloków, tryby precyzyjne, pre-addery, opcje kaskadowe/topologiczne oraz zachowanie mapowania dla twoich rdzeni matematycznych
• Pamięć na chipie: BRAM/URAM (lub M20K równoważniki), całkowita pojemność, tryby portów, przepustowość na zegarze i wzory kontencji
• I/O o wysokiej prędkości: klasa SERDES, liczba torów, maksymalna szybkość linii, opcje zegara referencyjnego oraz wsparcie protokołu związane z twoim przypadkiem użycia
• Pamięć zewnętrzna: warianty DDR3/DDR4/LPDDR, dojrzałość kontrolera, zachowanie kalibracyjne oraz założenia marginesu SI na poziomie płytki
• Opóźnienie i deterministyczność: cel end-to-end, budżet na każdy etap, tolerancja jittera i strategia CDC (w tym jak resetowanie przechodzi przez domeny)
• Zasięg mocy/termalny: szacunki dla najgorszego przypadku przełączania, tryby zasilania transceivera, założenia dotyczące chłodzenia oraz zakres otoczenia
Rzeczywiste projekty FPGA często pokazują, że dopasowanie do urządzenia nie gwarantuje niezawodnej pracy z wysoką prędkością. Projekty, które wydają się akceptowalne przy 70–80% wykorzystania, mogą stać się niestabilne po dodaniu logiki debugowania, ochrony CDC, FIFO, obsługi błędów i marginesu czasowego potrzebnego do praktycznej pracy.
Jeśli twój zespół kiedykolwiek stracił tydzień z powodu zatorów trasowania, zrozumienie potrzeby zwiększenia jednego rozmiaru urządzenia jest łatwe do przyjęcia. Przekład kosztów zwykle nie jest liniowy: nieco większa część może przynieść łagodniejsze czasy, mniej iteracji narzędzi oraz mniej nocnych rekonstrukcji.
Traktuj przepływ narzędzi jak wymaganie, którego nie można zignorować
Przepływ narzędzi zwykle jest ukrytym czynnikiem rozdzielającym solidny plan od planu, który ciągle się opóźnia. Ludzie często nie doceniają, jak wiele emocjonalnego wysiłku idzie na wolne lub nieprzewidywalne iteracje, szczególnie gdy budowa zajmuje godziny, a tryb awarii jest niejasny.
Lista kontrolna oceny przepływu narzędzi:
• Prędkość iteracji: czas syntezowania + miejsce/trasowanie + czas bitstreamu na twoim sprzęcie CI, a nie na maszynie demo dostawcy
• Zachowanie zamknięcia czasowego: trendy QoR, stabilność między nasionami i wrażliwość na małe zmiany ograniczeń
• Ograniczenia i obserwowalność: jasność SDC/XDC, dokładność modelowania zegara, obsługa ścieżek fałszywych/wielocyklicznych oraz jak łatwe do debugowania są naruszenia
• Instrumentacja debugowania: przepływ wstawiania analizatora logiki, elastyczność sondy, głębokość wyzwalania i jak często musisz ponownie kompilować, aby obserwować sygnały
• Dopasowanie środowiska: obsługiwane wersje systemu operacyjnego, kompilacje bez głowy, tarcia licencyjne oraz jak dobrze pasuje do przepływu pracy twojego zespołu
• Przyjazność CI/VCS: powtarzalność, deterministyczne wyjścia (tak bardzo, jak pozwalają na to narzędzia), możliwość skryptowania i ból aktualizacji
Zanim się zobowiążesz, przeprowadź próbę zamknięcia czasowego na czymś reprezentatywnym (nie zabawce). Uwzględnij swoje rzeczywiste zegary, przynajmniej jeden interfejs pamięci zewnętrznej oraz przynajmniej jeden blok I/O o wysokiej prędkości. Śledź:
• Czas kompilacji rzeczywistego zegara na iterację
• Stabilność slacka w kilku nasionach
• Jak szybko inżynier może zdiagnozować pierwsze trzy problemy z czasem bez wiedzy plemiennej
Ten eksperyment ma tendencję do wytwarzania rodzaju klarowności, jakiej nie zapewniają listy kontrolne. Odsłania również, czy Twój zespół będzie czuł się stabilnie, czy ciągle spięty podczas fazy integracji.
Dostępność IP i licencjonowanie: gdzie harmonogramy zwykle się napiętniają
Nawet gdy surowe zasoby FPGA wyglądają podobnie, harmonogramy często zależą od rzeczywistości IP. To tutaj zespoły mogą czuć się zaskoczone: rdzeń istnieje, ale model licencjonowania, wysiłek integracyjny lub jakość dokumentacji sprawia, że staje się to wolnym grindem.
Lista kontrolna IP i licencjonowania:
• Stosy protokołów: PCIe, Ethernet MAC/PCS, JESD204, kontrolery DDR i wszelkie niszowe interfejsy, na których polegasz
• Warunki licencji: przypisanie do węzła vs latający, dodatki funkcjonalne, implikacje dotyczące serwera budowy/CI oraz wszelkie ograniczenia dotyczące uruchomienia lub wdrożenia
• Projekty referencyjne: liczby linii, plan zegarowy, sekwencjonowanie resetu, architektura DMA oraz czy pasuje do granic Twojego systemu
• Horyzont wsparcia: oczekiwania dotyczące długoterminowego utrzymania, częstotliwość łatek oraz sposób, w jaki problemy są klasyfikowane
Subtelny punkt, którego zespoły uczą się w trudny sposób: dostępne IP to nie to samo co IP na zasadzie drop-in. Pokazy w laboratoriach mogą ukryć pracę integracyjną potrzebną do osiągnięcia celów dotyczących opóźnienia, buforowania i zegarowania. Planowanie czasu na walidację i preferowanie IP z bezpośrednią dokumentacją oraz znanymi, dobrymi przykładami często zmniejsza poziom stresu później, nawet jeśli wstępna ocena wydaje się wolniejsza.
Ekosystem Płyt, Ryzyko Włączenia i Komfort Znanych Platform
Wybór FPGA jest związany z rzeczywistością płytki. Podczas włączenia, czas zwykle znika w niepewności platformy zamiast RTL: jedno niedopilnowane ograniczenie zegarowe, zależność resetu, która nie była oczywista, lub kanał transceivera, który jest marginalny tylko w określonych temperaturach.
Lista kontrolna płyty i platformy
• Płyty ewaluacyjne i platformy referencyjne: dostępność, stabilność rewizji oraz czy projekt jest szeroko stosowany w terenie
• Wskazówki dotyczące dostarczania energii: cele PDN, podejście do odsprzęganiu, oczekiwania dotyczące sekwencjonowania szyn oraz założenia dotyczące tolerancji
• Referencje dotyczące układów wysokiej szybkości: wytyczne dotyczące trasowania transceiverów, notatki dotyczące zgodności oraz sprawdzone staki
• Dostęp do debugowania: stabilność JTAG, tryby uruchamiania/konfiguracji, wsparcie dla flash konfiguracji oraz widoczność w szynach/zegary
• Reaktywność wsparcia: kanały dostawcy, wskaźnik sygnału do szumu w społeczności oraz czas reakcji na problemy z narzędziami/IP
Używanie szeroko przyjętej platformy z udowodnionymi projektami referencyjnymi może sprawić, że włączenie systemu będzie bardziej zorganizowane i przewidywalne. Takie podejście pomaga przejść od ogólnej niepewności do krok-po-kroku mierzalnej weryfikacji, poprawiając efektywność rozwoju.
Zamykanie czasowe
Zamykanie czasowe to miejsce, w którym różnice między dostawcami stają się namacalne, szczególnie gdy wykorzystanie rośnie, a wiele domen zegarowych współdziała. Na tym etapie postępy w projektowaniu mogą pozostać stabilne i przewidywalne lub stać się trudne, gdy niewielkie zmiany powodują dużą wariację czasową.
• Skalowanie zatłoczenia: jak presja trasowania rośnie wraz ze wzrostem wykorzystania i gdzie zaczyna się jej nagły wzrost
• Przewidywalność Fmax: jak często umiarkowane ograniczenia przybliżają Cię do celu, w porównaniu do wymagania dużego ręcznego dostrojenia
• Jakość raportowania: czy raporty czasowe wskazują na konkretne naprawy, a nie tylko długie listy wykroczeń
• Wytrzymałość: zachowanie w różnych warunkach PVT i w różnych sadzawkach wdrożeniowych
Zwykle bezpieczniej jest zakładać, że wysiłek zamknięcia rośnie nieliniowo w związku z gęstością. Po osiągnięciu określonego progu, niewielka zmiana RTL może spowodować, że luz przechodzi ze zdrowego na kruchy. Luz architektoniczny, potokowe przetwarzanie, selektywne planowanie pięter i wybór urządzenia z dodatkowymi możliwościami często przewyższa bohaterskie dostrajanie ograniczeń, którego nikt nie lubi utrzymywać.
Porównaj dokładny element
Specyfikacje zmieniają się w kolejnych generacjach i w ramach jednej rodziny. Dwa elementy o podobnych nazwach mogą zachowywać się na tyle inaczej, aby zakłócić plan, zwłaszcza gdy pojawiają się pakowanie, klasa prędkości i dojrzałość narzędzi.
• Klasa prędkości: osiągalne Fmax, zachowanie marginesu transceivera oraz różnice w modelach czasowych
• Opakowanie: liczba I/O, rozmieszczenie banków, wpływ SI, zachowanie cieplne oraz ograniczenia montażowe
• Ograniczenia funkcji SKU: wyłączone bloki, zmniejszona zdolność transceivera, współczynniki pamięci lub ograniczenia protokołów w niektórych wariantach
• Dojrzałość narzędzi: poziom wsparcia urządzenia, częstotliwość wydania oraz czy Twój zespół może ustandaryzować na stabilnej wersji narzędzia
Praktyczna metoda porównawcza:
• Modele czasowe dostawcy dopasowane do Twoich rzeczywistych zegarów i interfejsów
• Szacowanie mocy przy użyciu realistycznych częstości przełączania, cykli pracy i ustawień transceivera
• Ograniczenia pinów/banków dostosowane do wymagań Twojej płyty i mapy złącz
• Wersje narzędzi, z którymi Twoja organizacja może funkcjonować przez cały okres realizacji produktu (w tym CI)
Ramy decyzyjne, które mają tendencję do utrzymywania się, gdy sprawy stają się stresujące
Kiedy presja harmonogramu rośnie, ramy oparte na pomiarach pomagają uniknąć decyzji podyktowanych żalem. Pomaga to również zespołowi czuć się bardziej pewnie, ponieważ decyzje mają ślad papierowy powiązany z zaobserwowanymi wynikami, a nie optymizmem.
Zrównoważony porządek wyboru:
1) Zablokuj mierzalne wymagania: zasoby, I/O, pamięć, opóźnienie i budżet mocy/termalny.
2) Prototypuj najtrudniejszy podsystem dla każdego kandydata: zachowanie czasowe + proces debugowania + pętla budowy/CI.
3) Oceń dojrzałość IP i licencjonowanie w stosunku do swojego planu integracji, a nie streszczeń marketingowych.
4) Wybierz opcję z zapasem i najprzewidywalniejszą pętlą iteracyjną, a nie tę, która ledwo spełnia minimum.
Kluczowym wnioskiem jest to, że najlepszy FPGA rzadko jest tym z najbardziej efektownymi danymi w nagłówkach. Zespoły zazwyczaj poruszają się szybciej i z mniejszymi wątpliwościami, gdy platforma wspiera stabilną konwergencję, powtarzalne budowy i łatwe do utrzymania rozwiązania przez cały okres życia produktu.
Główne Narzędzia

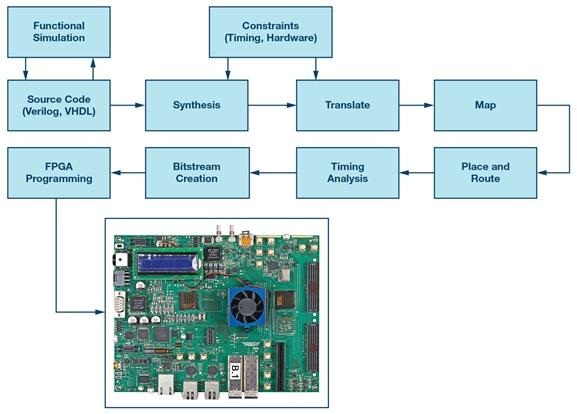
Rola Vivado w Przepływie Pracy FPGA
Vivado ma tendencję do stawania się operacyjnym centrum projektu FPGA Xilinx, nie dlatego, że jest efektowne, ale dlatego, że to tam każda zasada w końcu zostaje poddana próbie w kontekście rzeczywistości narzędziowej. Przetwarza HDL i ograniczenia, produkuje listę netlist, przeprowadza umiejscowienie i trasowanie, równocześnie balansując zasady czasowe i projektowe, a następnie generuje strumień bitów, który programuje urządzenie.
Praktycznym sposobem na zrozumienie Vivado jest postrzeganie go jako dwóch połączonych systemów: systemu konwersji RTL na netlistę oraz optymalizatora implementacji fizycznej. To wyjaśnia, dlaczego logicznie poprawne RTL może nadal produkować niestabilne lub niespójne wyniki, gdy ograniczenia są niekompletne, definicje zegarów są niedokładne lub struktura projektu powoduje trudności w trasowaniu i synchronizacji.
Większość projektów podąża za znanym procesem, nawet gdy szczegóły różnią się w zależności od rodziny urządzeń i stylu przepływu.
• Synteza: przekształca RTL w reprezentację na poziomie bramek i inferuje struktury specyficzne dla urządzenia.
• Implementacja: wykonuje umiejscowienie, trasowanie oraz optymalizację sterowaną czasowo w ramach ograniczeń fizycznych.
• Generacja strumienia bitów: emituje obraz konfiguracji i krzyżowo sprawdza wdrożony wynik w stosunku do ograniczeń i zasad narzędziowych.
Harmonogram ma tendencję do stawania się napięty, gdy strumień bitów jest produkowany raz, ale gdy zespół potrzebuje, aby strumień bitów działał jak niezawodne wyjście: podobne wyniki przy odbudowach, marginesy czasowe, które wytrzymują na docelowej klasie prędkości, oraz stabilność przy wprowadzaniu małych poprawek RTL dla funkcjonalnych poprawek. Wtedy to, co zbudowano wczoraj, przestaje być pocieszające.
Zespoły, które poruszają się szybciej z biegiem czasu, zazwyczaj przestają traktować raporty jako papierkową robotę i zaczynają traktować je jak dowody inżynieryjne. Gdy artefakty budowy są zbierane w sposób spójny, dyskusje projektowe stają się mniej emocjonalne i bardziej konkretne, co jest ulgą, gdy terminy się zbliżają.
• Raporty syntezy/implementacji: wykorzystanie, wywnioskowane elementy, ostrzeżenia i podsumowania strukturalne.
• Wyniki czasowe: WNS/TNS, końce niesprawne, szczegółowe ścieżki i podsumowania interakcji zegarowych.
• Ograniczenia XDC: zegary, zasady I/O, wyjątki i fizyczne przypisania pinów.
• Wdrożone punkty kontrolne (DCP): reprodukowalne zrzuty, które wspierają szybkie iteracje i kontrolowane eksperymenty.
Wzór, który pojawia się w rzeczywistej pracy, to to, że schludny, wewnętrznie spójny zestaw raportów często przewiduje płynniejszy postęp niż pojedynczy zielony banner "PASS". Banner może ukrywać kruchość; raporty zazwyczaj nie.
Instalacja i Konfiguracja Środowiska
Ustawienie, które jedynie uruchamia GUI, jest łatwe do świętowania i łatwe do żalu później. Ustawienia, którym zespoły ufają, są nudne w dobry sposób: zachowują się tak samo pod automatyzacją, są spójne na różnych maszynach i nie zaskakują po aktualizacji narzędzia.
Wybierz edycję Vivado ML, która odpowiada Twoim celom urządzenia, a następnie włącz tylko rodziny urządzeń, które naprawdę planujesz zbudować. Dzięki temu ograniczysz użycie dysku i czas indeksowania, a także zmniejszysz prawdopodobieństwo przypadkowych błędów konfiguracyjnych między rodzinami, które mogą zmarnować popołudnie.
W zespołach rozwijających wiele płyt, utrzymanie zdefiniowanej listy obsługiwanych urządzeń dla każdego projektu pomaga utrzymać rozwój bardziej kontrolowany i spójny niż poleganie na jakichkolwiek narzędziach lub częściach, które mogą być zainstalowane.
Wyjścia Vivado mogą się zmieniać między wersjami, ponieważ algorytmy umiejscowienia, trasowania i synchronizacji ewoluują, a błędy są naprawiane (lub zastępowane innymi błędami). Wiele zespołów uzyskuje spokojniejsze budowy, przypinając jedną wersję narzędzia do gałęzi wydań i aktualizując w zaplanowanych krokach, a nie dryfując w ciągłości.
Przy próbie użycia nowszej wersji, zespoły często porównują praktyczne sygnały zdrowia narzędzi przed przyjęciem ich jako nowej bazy: marginesy czasowe, zmiany wykorzystania, różnice ostrzegawcze oraz wszelkie nowe wiadomości o pokryciu ograniczeń. Czas spędzony na tym porównaniu jest zazwyczaj prostszy niż kłócenie się później w cyklu o to, czy czas nagle się pogorszył bez powodu.
W przypadku komend budowlanych, systemów CI i wspólnych serwerów budowlanych, środowisko deweloperskie musi zachowywać się spójnie w całym systemie, zamiast polegać na konfiguracjach poszczególnych maszyn.
• Skrypty ustawień: źródło odpowiednich ustawień narzędzi, aby ścieżki, biblioteki i zależności czasowe rozwiązywały się spójnie.
• Przepływy z wykorzystaniem Tcl: preferuj budowy skryptowe dla powtarzalnych uruchomień, jednolitego raportowania i integracji CI.
• Dyscyplina interfejsu budowy: utrzymuj wejścia i wyjścia w stabilności, aby zmiany były świadome i możliwe do przeglądania.
Powszechny przebieg pracy dewelopera polega na najpierw ukończeniu stabilnej budowy GUI w celu weryfikacji projektu, a następnie przejściu do przepływu opartego na Tcl, aby proces budowy nie opierał się już na ustawieniach GUI, danych buforowanych ani różnicach między maszynami deweloperskimi.
Raporty, które będziesz chciał przeczytać jak diagnostykę
Większość momentów awarii projektu nie jest tajemnicza przez długi czas, jeśli raporty są czytane jako historia tego, co narzędzie uznało. Ostrzeżenia, pokrycie ograniczeń i ścieżki czasowe dokumentują tryb awarii na pierwszy rzut oka, chociaż nie zawsze w najbardziej przyjaznej kolejności.
Zespoły rozwijają się najszybciej, gdy traktują wyjścia Vivado jako codzienną pętlę informacji zwrotnej, a nie coś, co otwierają tylko, gdy budowa się psuje.
Te raporty są często pierwszym miejscem, w którym widoczny staje się rozjazd intencji, a to może być dziwnie uspokajające: przynajmniej problem jest konkretny.
• Wykorzystanie zasobów: LUT, FF, BRAM, DSP, URAM w porównaniu z limitami urządzenia i zapasem.
• Kontrole wniosków: nieoczekiwane style RAM, brak wniosków DSP, zaskakujące mapowanie prymitywów.
• Strukturalne czerwone flagi: sieci o dużym fanout, szerokie multipleksowanie, długie łańcuchy kombinacyjne.
• Ostrzeżenia: wnioskowanie latch, niepełne obsługiwanie czułości, niepodłączona lub przycięta logika.
Wnioskowanie latch i niezamierzone długie ścieżki kombinacyjne często pojawiają się w praktyce. Narzędzie zaimplementuje je bez narzekań, co może wydawać się mylące, gdy później czas odmawia współpracy w sposób, który wygląda na losowy, dopóki raporty ze ścieżek nie zostaną przeczytane.
Zamknięcie czasowe staje się mniej stresujące, gdy zespół wie, co narzędzie optymalizuje i dlaczego wybiera pewne kompromisy.
• Sygnały slack: WNS jako najgorsza pojedyncza naruszenie; TNS jako całkowity rozkład naruszeń.
• Analiza ścieżek: gdzie gromadzi się opóźnienie (głębokość logiki, routowanie, taktowanie lub założenia ograniczeń).
• Modelowanie zegara: czy ścieżki są analizowane zgodnie z zamierzeniem, ignorowane lub grupowane niewłaściwie.
Jedną z subtelnych lekcji, które doświadczone zespoły internalizują, jest to, że ból czasowy jest często najpierw problemem modelowania ograniczeń, a dopiero potem problemem RTL. Gdy model zegara jest błędny, może spędzać dni, optymalizując błędne końce, i wciąż wydaje się, że narzędzie nie słucha.
Luki w ograniczeniach są powtarzającymi się przestępcami, częściowo dlatego, że nie zawsze wyglądają dramatycznie, dopóki projekt nie jest znacznie zaawansowany.
• Luki w definicji zegara: brakujące lub niepoprawne główne zegary.
• Luki w generowanych zegarach: podzielone/pomnożone/przekazywane zegary, które nie zostały zadeklarowane, zmuszając narzędzie do zgadywania.
• Luki w definicji I/O: brakujące ograniczenia I/O, które prowadzą do optymistycznych założeń i późniejszych niespodzianek na poziomie płyty.
• Niewłaściwe użycie wyjątków: brakujące wyjątki lub wyjątki, które są zbyt szerokie, aby były wiarygodne.
Pragmatycznym nawykiem jest traktowanie XDC jako żywej specyfikacji, a nie pliku łatki. Gdy wyjątki są wprowadzane, zespoły, które lepiej śpią, tendencją utrzymywania ich wąskich, wyjaśnionych i związanych z rzeczywistą relacją czasową, zamiast używać ich do stłumienia naruszeń, które zasługują na dokładne przyjrzenie się.
Strategia ograniczeń XDC
Plik XDC to miejsce, w którym intencje projektowe muszą stać się explicite. Gdy jest nieco błędny, wynikowe zachowanie czasowe może wyglądać chaotycznie, mimo że narzędzie działa w pełni deterministycznie.
Definiuj zegary explicite, a następnie zweryfikuj, czy narzędzie je propagowało tak, jak oczekiwałeś. Problemy z modelem zegara są często łatwiejsze do skorygowania niż głębsze problemy z architekturą czasową, co sprawia, że są prostsze do rozwiązania podczas analizy czasowej i debugowania.
• Główne zegary: zdefiniowane z pinów lub z wyjść MMCM/PLL.
• Generowane zegary: zdefiniowane dla podzielonych, pomnożonych lub przekazywanych domen.
• Asynchroniczne relacje: zadeklarowane za pomocą grup zegarowych lub wyraźnych relacji.
Na rzeczywistych płytach, jeden brakujący zegar generowany może wyprodukować mylący obraz czasowy, który spala dni, zwłaszcza gdy narzędzie optymalizuje w kierunku końców, które nigdy nie miały być analizowane razem.
Ograniczenia I/O kształtują elektryczne i czasowe założenia, które wykorzystuje narzędzie, i mogą cicho decydować o tym, czy sukces laboratorium staje się „sukcesem systemu”.
• Standardy elektryczne: standardy I/O i napięcia dostosowane do konstrukcji płyty.
• Dyscyplina pinów: zablokuj lokalizacje pinów, gdy mapowanie się ustabilizuje, aby uniknąć rotacji.
• Czas interfejsu: opóźnienia wejścia/wyjścia, które odzwierciedlają zewnętrzne urządzenie, a nie domyślne ustawienia narzędzia.
Znanym rozczarowaniem na późnym etapie jest: spełnił wymagania czasowe w budowie, ale interfejs zawodzi w rzeczywistym ruchu. Ten wynik często można prześledzić do domyślnych założeń I/O, które nigdy nie zostały zaktualizowane, aby odpowiadały czasowemu budżetowi płyty i zewnętrznego urządzenia.
Wyjątki mogą wyjaśnić zamiar, a także mogą stworzyć kruchą iluzję postępu, jeśli przetrwają swoje pierwotne uzasadnienie.
• Fałszywe ścieżki: używane tylko wtedy, gdy ścieżka na pewno nie jest częścią funkcjonalnego czasu.
• Ścieżki wielokrotne: używane tylko wtedy, gdy relacja przechwytywania rzeczywiście obejmuje wiele cykli i jest udokumentowana.
• Higiena wyjątków: zachowaj zestaw mały, przeglądaj go po ważnych zmianach RTL/pipeline i wycofaj przestarzałe wpisy.
Niektóre z najdroższych błędów czasowych pochodzą z wyjątków, które były kiedyś dokładne, a następnie cicho stały się niedokładne po zmianie w pipeline. Narzędzie będzie działać bez skargi, co właśnie sprawia, że ten tryb awarii jest tak nieprzyjemny.
Typowe wzorce awarii i jak je efektywnie rozwiązywać
Pewne problemy powtarzają się w różnych projektach, niezależnie od tego, czy aplikacja dotyczy sieci, wizji, kontroli czy przyspieszenia. Wczesne rozpoznanie wzoru zwykle zmniejsza emocjonalne obciążenie debugowania, ponieważ zespół może przejść od "dlaczego to się dzieje" do "który podręcznik ma zastosowanie".
Ta sytuacja często wydaje się, że narzędzie jest uparte, ale przyczyny zazwyczaj można prześledzić.
• Głębokość kombinacyjna: długie ścieżki spowodowane brakiem lub niewystarczającym pipeliningiem.
• Nacisk na fanout: kontrolne sieci o wysokim fanout, które korzystają z replikacji, buforowania lub restrukturyzacji.
• Modelowanie ograniczeń: definicje zegara lub relacje, które niewłaściwie charakteryzują to, co powinno być analizowane.
Sekwencja, która zazwyczaj dobrze działa, to: walidacja modelu czasowego (zegary i relacje), skupienie się najpierw na najgorzej działających punktach końcowych, a następnie rozszerzenie w kierunku zmian architektonicznych tylko wtedy, gdy dowody ścieżek to popierają.
To jedno z bardziej demoralizujących doświadczeń w pracy z FPGA, głównie dlatego, że wydaje się, że rzeczywistość jest niesprawiedliwa. Zwykle po prostu symulacja nie testowała tych samych trybów awarii.
• Zachowanie CDC/reset: sekwencjonowanie resetu i przemiany domen zegarowych, które symulacja rzadko realistycznie wykonuje.
• Założenia I/O: nieograniczone lub źle ograniczone I/O, które produkuje marginalne prawdziwe interfejsy.
• Zachowanie inicjalizacji: poleganie na wartościach początkowych, które nie mapują się czysto na zachowanie uruchamiania urządzenia.
Zespoły, które stają się bardziej stabilne, wnosi strategię CDC i resetu na wczesnym etapie dyskusji projektowej, traktując je jako część architektury projektu, a nie jako fazę czyszczenia po ukończeniu „prawdziwej logiki”.
Ten problem jest powszechny, ponieważ umieszczanie i trasowanie reagują ostro na zmiany struktury netlisty, nawet gdy zmiana funkcjonalna wydaje się niewielka.
• Wrażliwość netlisty: małe refaktory mogą zmieniać decyzje o pakowaniu, umiejscowieniu i zatorach trasowania.
• Dryfującym ograniczeń: małe zmiany w XDC (lub brak pokrycia) mogą zaostrzyć zmienność czasową.
• Nawyk łagodzenia: inkrementalne wdrażanie, selektywne zachowanie hierarchii i stabilne ograniczenia.
Gdy zespoły przyjmują te nawyki łagodzenia, iteracje stają się bardziej przewidywalne, co zmniejsza pokusę zamrożenia projektu przedwcześnie z obawy przed ponownym złamaniem czasu.
Rozważania dotyczące licencjonowania
Licencjonowanie zazwyczaj staje się tematem rozmowy, gdy projekt napotyka ograniczenia dotyczące pokrycia urządzeń lub gdy zaawansowane funkcje są potrzebne do konkretnego przepływu pracy.
• Standard: często współczesne z płytami edukacyjnymi w zakresie podstawowym i średnim oraz podstawowymi procesami.
• Enterprise: często odpowiada szerszemu wsparciu urządzeń i zaawansowanym możliwościom.
Dla zespołów, elastyczne licencje poparte serwerem licencyjnym są często łatwiejsze do skalowania niż licencje blokowane na węźle, szczególnie gdy kompilacje działają na współdzielonych maszynach, dedykowanych serwerach kompilacyjnych lub runnerach CI. Wiele zespołów woli dostosować licencjonowanie do mapy drogowej urządzenia wcześniej niż później, ponieważ niespodzianki dotyczące licencji mają tendencję do pojawiania się, gdy zmiana urządzeń jest już kosztowna i politycznie trudna.
Spójna pętla inżynieryjna zazwyczaj przewiduje stabilniejszy postęp niż jakakolwiek jednorazowa sprytna optymalizacja: trzymaj ograniczenia w zgodzie z rzeczywistością, regularnie czytaj raporty (nawet gdy wolałbyś tego nie robić), naprawiaj przyczyny źródłowe zamiast tłumić objawy i utrzymuj reproducybilność kompilacji. Gdy ta pętla jest ustalona, Vivado wydaje się mniej czarną skrzynką, a bardziej panelem instrumentów, a zamknięcie czasowe przechodzi z ostatniej chwili na coś, co zespół może zarządzać świadomie.
Portfolio i ekosystem Xilinx

Wybór wśród urządzeń Xilinx zazwyczaj przebiega gładziej, gdy punktem wyjścia jest otaczająca integracja (procesory, interfejsy pamięci, ścieżka rozruchowa i zależności na poziomie płyty), a nie tylko porównanie surowych całkowitych LUT. Ta perspektywa zazwyczaj odpowiada temu, jak realne harmonogramy i realne ryzyka się ujawniają.
Dyskretny FPGA sprawdzi się, gdy zespół chce mieć pełną kontrolę nad architekturą płyty, a obciążenia składają się na deterministyczne zachowanie sprzętu z minimalną powierzchnią oprogramowania. Zespół SoC z rodziny Zynq sprawdzi się, gdy projekt korzysta z CPU, które znajduje się blisko logiki akceleracji, aby kontrola i ścieżka danych mogły rozwijać się razem, nie zamieniając płyty w negocjację z wieloma układami. Moduł w stylu Kria SOM sprawdzi się, gdy celem jest szybkie działanie i ograniczenie niepewności związanej z uruchomieniem płyty poprzez traktowanie obliczeń, pamięci i pamięci rozruchowej jako wstępnie zatwierdzonego elementu budowlanego.
Dyskretny FPGA zazwyczaj nadaje się do:
• maksymalnej kontroli nad projektem płyty
• deterministycznych potoków z ograniczoną zależnością od oprogramowania
SoC Zynq zazwyczaj nadaje się do:
• ścisłego połączenia CPU+akcelerator
• zintegrowanego obliczeń/kontroli na jednym urządzeniu
• iteracyjnej ewolucji HW/SW
Kria SOM zazwyczaj nadaje się do:
• krótszego czasu do produktu
• zmniejszonej ekspozycji na poziomie płyty poprzez użycie zwalidowanego podsystemu obliczeniowego
Zwykłe FPGA często dobrze sprawdzają się, gdy problem jest spowodowany naciskiem na zamknięcie czasowe, nietypowymi potrzebami I/O lub potokami strumieniowymi, które najlepiej działają jako sprzęt o stałej funkcji. Przewidywalne opóźnienia i zorganizowane ścieżki danych często poprawiają kontrolę, weryfikację i debugowanie, szczególnie gdy architektura pozostaje dobrze zorganizowana.
Urządzenia samodzielne często pojawiają się w:
• interfejsowaniu czujników
• kontroli silników
• przetwarzaniu pakietów o umiarkowanej prędkości
• mostkowaniu protokołów
W terenie powracającym źródłem frustracji nie jest sam RTL, ale otaczające zobowiązania związane z płytą, które przychodzą cicho, a następnie dominują na ścieżce krytycznej. Szyny zasilania, strategia konfiguracyjna i rozruchowa, generacja zegara, układ pamięci zewnętrznej (jeśli istnieje) oraz dostęp do debugowania mogą stać się ograniczeniami, które kształtują cały produkt. Jedna praktyczna zasada to, że im prostsza historia pamięci zewnętrznej i im mniej zaangażowanych transceiverów wysokiej prędkości, tym bardziej satysfakcjonujące staje się doświadczenie z samodzielnym FPGA. Jak tylko zewnętrzne DDR i wielostopniowe przepływy rozruchowe staną się nieuniknione, atrakcyjność integracji SoC lub modułu zaczyna wydawać się mniej cechą, a bardziej ulgą.
Rodziny zoptymalizowane kosztowo zazwyczaj dążą do zmierzonego połączenia LUT, BRAM i DSP przy ograniczonych budżetach energetycznych. Pojawiają się często w produktach, w których zespół inżynieryjny chce szanownej wydajności bez płacenia podatku za płytę i cieplarnie, który wiąże się z ekstremalnymi interfejsami.
Wspólne obszary lądowania obejmują:
• kontrolę wbudowaną
• agregację I/O w średnim zakresie
• przetwarzanie sygnałów o umiarkowanej prędkości
Korzyścią nie jest tylko cena jednostkowa, zespoły często doceniają, że te części ułatwiają pozostawanie w ramach limitów termicznych bez uciekania się do agresywnego chłodzenia, a także mogą zapobiec przekształceniu PCB w projekt o wysokiej prędkości. W tym samym czasie budowy w terenie regularnie uczą lekcji, która może być nieco niewygodna: tańsze urządzenie może generować wyższe całkowite wydatki, jeśli zmusza do późnych kompromisów projektowych. Gdy margines czasowy jest cienki, niewielkie dostosowania, zmiana standardu I/O, zmiana routingu zegara, zmiana planu piętra, mogą wpłynąć na weryfikację i niepokój związany z harmonogramem. Dla tych urządzeń zespoły zazwyczaj oszczędzają czas, ustalając planowanie domen zegarowych, strategię CDC i zachowanie resetu na wczesnym etapie, zamiast liczyć na późne mikrooptymalizacje, które uratują plan.
SoC Zynq
Urządzenia Zynq łączą przetwarzanie ARM z programowalną logiką, co pozwala na podział projektu na oprogramowanie w warstwie kontrolnej i akcelerację w warstwie danych w sposób, który wydaje się naturalny dla wielu zespołów produktowych. To nie tylko poprawia wygodę, ale też przekształca przepływ pracy. Zespoły mogą rozpocząć od odniesienia opartego na oprogramowaniu dla zaufania funkcjonalnego, a następnie przenieść gorące ścieżki do sprzętu, gdy wymagania dotyczące przepustowości i opóźnienia stają się mniej negocjowalne.
W wdrożeniach, które starzeją się dobrze, CPU rzadko „zastępuje” sprzęt, ma tendencję do stabilizacji produktu. Procesor często kończy z obsługą konfiguracji, telemetry, aktualizacji w terenie, polityki bezpieczeństwa i łączności brzegowej, podczas gdy fabric obsługuje deterministyczne potoki. To rozdzielenie może być emocjonalnie uspokajające dla konserwatorów: oprogramowanie absorbuje zmiany, sprzęt pozostaje stabilny, a wydania wydają się mniej jak gra na giełdzie.
CPU zazwyczaj obsługuje:
• konfigurację
• telemetry
• aktualizacje
• politykę bezpieczeństwa
• łączność brzegową
Fabric zazwyczaj obsługuje:
• deterministyczne potoki strumieniowe
• stabilne akceleratory
• ścieżki danych wrażliwe na opóźnienia
W miarę wzrostu gęstości obliczeniowej i coraz bardziej wymagających interfejsów, części w stylu Zynq UltraScale+ zmniejszają złożoność płytki i systemu, przyciągając rdzenie CPU, kontrolery DDR i interkonekty o wysokiej przepustowości bliżej fabric. To staje się atrakcyjne w projektach, które wymagają zarówno deterministyczności czasu rzeczywistego, jak i zdolnego środowiska programowego, zwłaszcza gdy obciążenie jest mieszanką, a nie pojedynczym czystym rdzeniem.
Częste przypadki użycia obejmują:
• analitykę brzegową
• fuzję wielu czujników
• mieszane potoki czasu rzeczywistego z AI
Szczegół, który zespoły z doświadczeniem uczą się szanować, to to, że „więcej fabric” niekoniecznie oznacza „więcej dostarczonej wydajności”. Projekty często napotykają na sufit przepustowości pamięci zanim zabraknie im DSP lub LUT. Projekty, które wcześnie decydują o topologii DMA, strategii buforowania i oczekiwaniach dotyczących spójności pamięci podręcznej, mają tendencję do osiągania stabilnej wydajności z mniejszym zamieszaniem niż projekty, które odkładają decyzje o przenoszeniu danych do późnej integracji.
Podział rzadko dotyczy tego, czy coś można przyspieszyć, bardziej chodzi o to, czy przyspieszenie się opłaca, biorąc pod uwagę wysiłek weryfikacyjny, złożoność sterowników i środowisk wykonawczych oraz jak często logiczne obwody mają być zmieniane. Zespoły często odczuwają tu „wciąganie w wojnę”: zbyt duże przesunięcie w kierunku sprzętu może spowolnić iterację, podczas gdy pozostawienie zbyt dużej ilości na CPU może sprawić, że cele przepustowości będą zawsze niemal na wyciągnięcie ręki.
Obciążenia, które często pozostają na CPU dłużej niż oczekiwano, obejmują:
• szybko zmieniającą się logikę
• złożone zachowania wymagające analizy
• funkcje z szybkim cyklem iteracji
Obciążenia, które często nagradzają wczesne przyspieszenie fabric, obejmują:
• stabilne algorytmy
• gęste obliczeniowo rdzenie
• przyjazne dla strumieni ścieżki danych
Pragmatycznym wzorcem jest rozpoczęcie od małego, kompleksowego fragmentu, często prostego pętli DMA w połączeniu z minimalnym akceleratorem, zanim zbuduje się pełny zestaw funkcji. Ten ograniczony prototyp ma tendencję do ujawniania problemów integracyjnych, które w przeciwnym razie pojawiają się późno i kosztownie: zachowanie przerwania, wyrównanie bufora, koszty utrzymania pamięci podręcznej oraz sufity przepustowości, które pojawiają się tylko pod stałym obciążeniem.
Kria SOM i modułowe platformy
Kria SOM pakują obliczenia, pamięć i pamięć uruchomieniową w gotowy podsystem, przekierowując wysiłek z uruchamiania płyty w kierunku inżynierii aplikacji. Zespoły często preferują to podejście, ponieważ zawiera ono niepewność: integralność sygnału, routowanie DDR, sekwencjonowanie zasilania i niezawodność uruchamiania są już zweryfikowane, co może sprawić, że wczesne pokazy wydają się mniej delikatne, a planowanie mniej spekulacyjne.
Podejście to zazwyczaj działa szczególnie dobrze, gdy różnicowanie tkwi w algorytmach, topologii I/O i niezawodności wdrożenia, a nie w niestandardowej płycie obliczeniowej. Może to również zmniejszyć tarcia między zespołami: prace związane ze sprzętem, oprogramowaniem układowym i aplikacją mogą przebiegać równolegle z mniejszą liczbą „zablokowanych przez uruchamianie” momentów.
Walidowana integracja SOM zwykle obejmuje:
• integralność sygnału
• routowanie DDR
• sekwencjonowanie zasilania
• niezawodność uruchamiania
Zespoły mogą skupić wysiłki na:
• różnicowaniu na płycie nośnej
• integracji oprogramowania układowego
• zachowaniu aplikacji
• wzmocnieniu wdrożenia
SOM często ma wyższą cenę za jednostkę niż całkowicie niestandardowa płyta, jednak całkowity koszt programu może nadal spadać, gdy harmonogramy są napięte lub ryzyko wydajności produkcji jest niekomfortowe. Mniej oczywista korzyść to przewidywalność cyklu życia: z modułem obliczenia mogą czasem być traktowane jako element wymienny w różnych wariantach produktu, co zmniejsza chaotyczność ponownego projektowania, gdy wymagania zmieniają się w trakcie.
Najspokojniejszym krokiem jest wczesne potwierdzenie, że margines termiczny SOM, ekspozycja I/O i przepustowość pamięci rzeczywiście odpowiadają zamierzonym obciążeniom, zamiast polegać na odczycie specyfikacji. Jeśli aplikacja okaże się ograniczona przepustowością, dostosowanie na późnym etapie zazwyczaj wydaje się jak pchanie na zamek, niedopasowanie między zapotrzebowaniem na akcelerator a podsystemem pamięci modułu po prostu dominuje.
Kontrole wczesnej dopasowalności zazwyczaj obejmują:
• envelope termiczny
• odsłonięte I/O
• utrzymywana przepustowość pamięci w porównaniu z wymogami obciążenia
Wdrożenie AI w ekosystemie
Vitis AI pomaga w przekształceniu wytrenowanych modeli w projekty inferencyjne oparte na FPGA, używając formatów o niższej precyzji, często INT8, i kompilując je dla architektur w stylu DPU. Szybko potwierdza to, czy model może działać na platformie FPGA. Rzeczywista wydajność jednak często w dużym stopniu zależy od projektowania systemu, szczególnie od ruchu danych i zarządzania pamięcią.
Przepustowość end-to-end jest zazwyczaj uzależniona od tego, jak konsekwentnie system może dostarczać dane do DPU. Strategia grupowania, układ tensorów, harmonogram DMA, podwójne buforowanie i rozmieszczenie pamięci często decydują o dostarczanym FPS bardziej niż obliczeniowa wartość dominująca. Zespoły, które traktują DPU jak stałego konsumenta strumienia, z starannie przygotowanymi buforami, mają tendencję do unikania powszechnego rozczarowania imponującymi teoretycznymi TOPS, ale rozczarowującymi wynikami na poziomie systemu.
Pokrętła kształtujące wydajność zwykle obejmują:
• strategię grupowania
• układ tensorów
• harmonogram DMA
• podwójne buforowanie
• rozmieszczenie pamięci
W wdrożeniach drobne wybory implementacyjne kumulują się w sposób, który może być trudny do przewidzenia na podstawie mikrobenchmarków laboratoryjnych. Niezgodne bufory mogą cicho redukować efektywną przepustowość. Nadmierna konserwacja pamięci podręcznej może pochłaniać czas CPU i powodować drgania. Rurociągi intensywnie kopiujące mogą zniweczyć wiele korzyści uzyskanych z kwantyzacji. Ugruntowane podejście polega na pomiarze przepustowości i opóźnienia na każdej granicy, a następnie skupieniu wysiłku na granicy, która obecnie jest najwęższa.
Użyteczne granice pomiarowe obejmują:
• czujnik do DDR
• DDR do akceleratora
• akcelerator do przetwarzania końcowego
Pomocną mentalną wizją jest postrzeganie pipeline'a AI jako ograniczonej sieci przepływowej. Z tym ujęciem, wybór urządzeń staje się mniej o dążeniu do największej liczby obliczeniowej, a bardziej o wyborze opcji, która łagodzi dominującą wąskie gardło i utrzymuje przewidywalne zachowanie rurociągu.
Ekosystem i wsparcie
Ekosystem Xilinx wykracza poza krzem w kierunku otaczającego wsparcia, które napędza zespoły: łańcuchy narzędzi, IP, wzorce referencyjne, płyty partnerskie i zasoby szkoleniowe. W środowiskach akademickich Program Uniwersytecki jest często doceniany, ponieważ zmniejsza powtarzające się trudności związane z konfiguracją, dostępem do narzędzi, dostępnością płyt i strukturą laboratorium, dzięki czemu wczesny postęp rzadziej utknie przez problemy związane z otoczeniem zamiast z nauką faktycznego inżynierii.
Elementy ekosystemu obejmują:
• łańcuchy narzędzi (Vivado, Vitis)
• katalogi IP
• wzorce referencyjne
• płyty partnerskie
• programy szkoleniowe
• zasoby Programu Uniwersyteckiego
Gdy opory związane z wdrożeniem są zmniejszone, uczniowie mogą poświęcić swoją energię na nawyki, które przekładają się bezpośrednio na pracę zawodową: rutyny zamykania czasowego, dyscyplinę pipeline'ów, strategię weryfikacji i ocenę współprojektowania sprzętu oprogramowania. Umiejętności te zwykle ujawniają swoją wartość podczas integracji, gdy wyniki są kształtowane bardziej przez szybkość iteracji i spójność systemu niż przez odizolowany benchmark jądra.
Umiejętności transferowalne obejmują:
• nawyki zamykania czasowego
• dyscyplinę pipeline'ów
• strategię weryfikacji
• współprojektowanie sprzętu i oprogramowania
Zasada selekcji, która pozostaje spójna w całej ofercie
Niezawodne podejście do wyboru zaczyna się od ograniczeń systemowych, a nie od poziomów marketingowych. Zespoły zazwyczaj podejmują jaśniejsze decyzje, gdy zapisują cele operacyjne i rzeczywistość projektu z wyprzedzeniem, a następnie wybierają poziom integracji, FPGA, Zynq SoC lub SOM, który zmniejsza największe źródła niepewności dla ich konkretnego programu. To często prowadzi do wyborów, które wydają się lepsze miesiące później, gdy integracja i tempo iteracji mają większe znaczenie niż porównanie cząstek na papierze.
Ograniczenia, które należy określić wcześniej, obejmują:
• cele opóźnienia
• potrzeby w zakresie trwałej przepustowości
• wymagania dotyczące interfejsów
• limity termiczne
• częstotliwość aktualizacji
• budżet weryfikacji
W wielu programach opcja, która utrzymuje ruch danych bezproblemowym i pętlę rozwoju bliskość, okazuje się być tą, która najlepiej się starzeje, nawet jeśli jej cena jednostkowa nie jest najbardziej atrakcyjna na pierwszy rzut oka.
Wnioski
Nauka projektowania FPGA Xilinx staje się łatwiejsza, gdy każdy projekt śledzi stabilny i powtarzalny proces. Silne wyniki zależą od czystego HDL, poprawnych ograniczeń, starannych kontroli czasowych, symulacji i walidacji na rzeczywistym sprzęcie. Rozpoczynając od prostych projektów i budując dobre nawyki debugowania, początkujący mogą rozwijać niezawodne umiejętności FPGA dla bardziej zaawansowanych systemów cyfrowych.
Często Zadawane Pytania [FAQ]
1. Dlaczego początkujący w FPGA często mają trudności, nawet gdy ich kod HDL wydaje się logicznie poprawny w symulacji?
Wiele wczesnych problemów z FPGA nie wynika z RTL, lecz z różnicy między założeniami symulacyjnymi a zachowaniem fizycznego sprzętu. Symulacja zwykle ukrywa problemy związane z ograniczeniami czasowymi zegara, synchronizacją resetu, standardami I/O, metastabilnością i zamykaniem czasowym. Projekt może symulować perfekcyjnie, a mimo to nie działać na sprzęcie, ponieważ narzędzia FPGA interpretują zegary inaczej, ograniczenia są niekompletne lub asynchroniczne wejścia są obsługiwane nieprawidłowo.
2. Dlaczego ograniczenia czasowe są uważane za kluczową część projektowania FPGA, a nie za końcowy krok optymalizacji?
Ograniczenia czasowe definiują, jak narzędzia FPGA interpretują zegary, relacje czasowe I/O, generowane zegary i asynchroniczne domeny. Bez dokładnych ograniczeń Vivado może optymalizować projekt, korzystając z błędnych założeń, prowadząc do mylących raportów czasowych i niestabilnego zachowania sprzętu. Wiele awarii FPGA występuje, nawet gdy logika jest poprawna, ponieważ zegary nie zostały poprawnie zadeklarowane, relacje czasowe I/O zostały zignorowane lub wyjątki zastosowano zbyt szeroko. W praktyce ograniczenia działają jako formalny opis zamiaru projektowego, pozwalając narzędziom budować sprzęt, który odpowiada rzeczywistemu zachowaniu elektrycznemu.
3. Dlaczego debugowanie FPGA często wymaga zarówno symulacji, jak i narzędzi na chipie, takich jak ILA?
Symulacja jest bardzo skuteczna w wykrywaniu błędów funkcjonalnych, ale nie może w pełni odzwierciedlić rzeczywistych efektów sprzętowych, takich jak drgania, asynchroniczne wejścia, opóźnienia na poziomie płyty, metastabilność i różnice w zasilaniu. Narzędzia do debugowania na chipie, takie jak Zintegrowany Analizator Logiczny (ILA), zapewniają wgląd w sygnały wewnętrzne FPGA podczas działania systemu w rzeczywistych warunkach. To pozwala na uchwycenie rzeczywistych przejść stanów, zachowań FIFO, handshake'ów i relacji czasowych bezpośrednio w urządzeniu. Łączenie symulacji z debugowaniem ILA tworzy pełniejsze zrozumienie, dlaczego sprzęt różni się od oczekiwanego zachowania.
4. Dlaczego doświadczeni inżynierowie FPGA preferują zdyscyplinowane, powtarzalne przepływy pracy zamiast ciągłych zmian w ustawieniach projektu?
Powtarzalne przepływy pracy zmniejszają niepewność i ułatwiają izolację awarii. Korzystanie z tej samej płyty rozwojowej, struktury zegarowej, strategii resetu i szablonu projektu pozwala inżynierom skupić się na rozwijanej logice, zamiast wielokrotnie debugować samo środowisko. Projekty FPGA obejmują wiele wzajemnie oddziałujących zmiennych, w tym ograniczenia, zegary, zachowanie syntez i konfigurację na poziomie płyty. Gdy zbyt wiele zmiennych zmienia się jednocześnie, debugowanie staje się nieprzewidywalne i emocjonalnie wyczerpujące. Stabilne przepływy pracy zwiększają pewność, ponieważ zmiany można śledzić do konkretnych decyzji projektowych, a nie do nieznanych różnic w otoczeniu.
5. Dlaczego projektowanie sprzętu FPGA jest fundamentalnie różne od tradycyjnego programowania oprogramowania?
Oprogramowanie wykonuje instrukcje sekwencyjnie, podczas gdy sprzęt FPGA działa poprzez równoległe struktury logiczne działające jednocześnie. HDL opisuje fizyczne zachowanie sprzętu zamiast sekwencji wykonania proceduralnego. Początkujący często oczekują zachowania podobnego do oprogramowania, a następnie czują się zdezorientowani, gdy wiele bloków sprzętowych reaguje równocześnie na tym samym zboczu zegara. Projektowanie FPGA kładzie więc nacisk na rurociągi, relacje czasowe, synchronizację, mapowanie zasobów i zachowanie w domenach zegarowych, zamiast jedynie na porządku instrukcji. Zrozumienie równoległości jest jednym z najważniejszych przesunięć mentalnych w inżynierii FPGA.
6. Dlaczego małe zmiany w RTL mogą nagle wywołać poważne problemy z zamykaniem czasowym w projektach FPGA?
Zachowanie czasowe FPGA w dużej mierze zależy od miejsca, zatorów w trasowaniu, rozkładu obciążenia, relacji zegarowych i fizycznego wykorzystania zasobów. Nawet małe modyfikacje RTL mogą zmienić to, jak narzędzia syntez i trasowania mapują logikę w urządzeniu. Z pozoru nieszkodliwa zmiana może zwiększyć nacisk na trasowanie, wydłużyć ścieżki kombinacyjne lub wpłynąć na decyzje dotyczące umiejscowienia w sposób, który znacząco zmniejsza margines czasowy. Ta wrażliwość staje się bardziej dotkliwa w miarę wzrostu wykorzystania, szczególnie gdy projekty zbliżają się do ograniczeń trasowania lub zegarowania.
7. Dlaczego projekty FPGA często są ograniczane przez realia na poziomie płyty, a nie tylko przez złożoność RTL?
W miarę rozwoju systemów FPGA, wyzwania związane z sekwencjonowaniem zasilania, układem DDR, generowaniem zegarów, zachowaniem cieplnym, integralnością sygnału i trasowaniem transceiverów często dominują w czasie rozwoju. RTL może działać poprawnie, podczas gdy otaczająca infrastruktura sprzętowa wprowadza niestabilność lub awarie integracji. Inżynierowie często odkrywają, że decyzje projektowe dotyczące płyty, sekwencjonowanie resetu oraz zachowanie interfejsu pamięci kształtują ogólny sukces projektu bardziej niż sam HDL. Jest to szczególnie prawdziwe w systemach o dużej prędkości zewnętrznej pamięci DDR i interfejsami SERDES.
8. Dlaczego wiele zespołów FPGA tak poważnie ocenia łańcuchy narzędziowe jak sam sprzęt FPGA?
Łańcuch narzędzi FPGA bezpośrednio wpływa na czas kompilacji, stabilność zamknięcia czasowego, efektywność debugowania, integrację CI oraz ogólną produktywność inżynieryjną. Wolne lub niespójne wyniki implementacji mogą dramatycznie zwiększyć czas iteracji i presję na harmonogram. Zespoły często oceniają jakość syntezy, klarowność raportu czasowego, instrumentację do debugowania oraz powtarzalność przed przystąpieniem do platformy. W rzeczywistych środowiskach deweloperskich przewidywalne kompilacje i stabilne zamknięcie czasowe często mają większe znaczenie niż izolowane specyfikacje FPGA dotyczące nagłówków.
9. Dlaczego platformy Zynq SoC i Kria SOM zmniejszają złożoność integracji w porównaniu do samodzielnych FPGA?
Zynq SoC łączą procesory ARM z programowalną logiką w jednym urządzeniu, co upraszcza komunikację między przyspieszeniem sprzętowym a oprogramowaniem. Kria SOM idą jeszcze dalej, integrując pamięć, pamięć rozruchową, sekwencjonowanie zasilania i zwalidowany sprzęt w prekwalifikowany moduł. Te podejścia zmniejszają ryzyko związane z trasowaniem DDR, niezawodnością rozruchu, projektowaniem dostarczania energii oraz uruchamianiem płyt. W efekcie zespoły mogą skupić się bardziej na zachowaniu aplikacji, a mniej na wyzwaniach związanych z integracją sprzętową na niskim poziomie.
10. Dlaczego udane wdrożenie AI oparte na FPGA w dużej mierze zależy od ruchu danych, a nie tylko od wydajności akceleratorów?
Akceleratory AI, takie jak DPU, mogą zapewniać wysoką teoretyczną przepustowość obliczeniową, ale rzeczywista wydajność często jest ograniczana przez przepustowość pamięci, harmonogramowanie DMA, zarządzanie buforami oraz efektywność ruchu tensorów. Źle zoptymalizowane potoki danych mogą głodzić akcelerator i dramatycznie zmniejszać efektywną FPS pomimo silnych możliwości obliczeniowych. Udane systemy AI oparte na FPGA koncentrują się więc mocno na podwójnym buforowaniu, topologii DMA, strategii grupowania, rozmieszczeniu pamięci oraz utrzymywanym przepływie danych między czujnikami, pamięcią DDR, akceleratorami i etapami przetwarzania końcowego.
Powiązany blog
-
Ile zer na milion, miliard, bilion?
![Ile zer na milion, miliard, bilion?]()
2024/07/29
Million reprezentuje 106, łatwo chwytana liczba w porównaniu do przedmiotów codziennych lub rocznych pensji. Miliard, równoważny 109, zaczyna roz... -
IRLZ44N MOSFET Arkusz, obwód, równoważny, pinout
![IRLZ44N MOSFET Arkusz, obwód, równoważny, pinout]()
2024/08/28
IRLZ44N to szeroko stosowany Mosfet Power N-Kannel.Znany z doskonałych możliwości przełączania, jest bardzo odpowiedni do wielu zastosowań, szcz... -
Temperatura akumulatora zbyt niska, ładowanie zatrzymało się.Jak to naprawić?
![Temperatura akumulatora zbyt niska, ładowanie zatrzymało się.Jak to naprawić?]()
2024/10/6
Problemy z ładowaniem baterii telefonu komórkowego są powszechne, ale można je skutecznie zarządzać.Temperatura odgrywa dużą rolę w wydajnoś... -
BC547 Tranzystor Kompleksowy przewodnik
![BC547 Tranzystor Kompleksowy przewodnik]()
2024/07/4
Tranzystor BC547 jest powszechnie stosowany w różnych zastosowaniach elektronicznych, od podstawowych wzmacniaczy sygnałowych po złożone obwody o... -
Kompleksowy przewodnik po SCR (prostownik kontrolowany krzem)
![Kompleksowy przewodnik po SCR (prostownik kontrolowany krzem)]()
2024/04/22
Kontroli prostownicy (SCR) lub Thyristors odgrywają kluczową rolę w technologii elektroniki energetycznej ze względu na ich wydajność i niezawod... -
LR621, SR621SW, 364, AG1 Equivivalents i zamienniki
![LR621, SR621SW, 364, AG1 Equivivalents i zamienniki]()
2024/07/15
Baterie przycisków LR621 i SR621SW są powszechne w kompaktowych urządzeniach elektronicznych, takich jak zegarki, małe zabawki, kalkulatory i zdal... -
Kompletny przewodnik po multiplekserach i ich rola w systemach cyfrowych
![Kompletny przewodnik po multiplekserach i ich rola w systemach cyfrowych]()
2025/09/20
Multipleksery są komponentami w systemach cyfrowych, zaprojektowanych do kierowania wieloma sygnałami wejściowymi do pojedynczej linii wyjściowej ... -
Podstawy obwodów OP-AMP
![Podstawy obwodów OP-AMP]()
2023/12/28
W skomplikowanym świecie elektroniki podróż do jej tajemnic niezmiennie prowadzi nas do kalejdoskopu komponentów obwodów, zarówno wykwintnych, j... -
Porównanie różnic i zastosowań NMOS i PMOS
![Porównanie różnic i zastosowań NMOS i PMOS]()
2024/11/15
Zrozumienie różnic między tranzystorami NMOS i PMO jest ważne w projektowaniu wydajnych obwodów.NMOS (NMOS-semiconductor) i PMOS (typ p-tlenku-tl... -
CR2450 vs CR2032 Porównanie: Wszystko, co musisz wiedzieć
![CR2450 vs CR2032 Porównanie: Wszystko, co musisz wiedzieć]()
2025/09/15
Baterie guzików, takie jak CR2450 i CR2032, zasilają wiele codziennych elektroniki, od zegarków i pilotów po urządzenia medyczne i przemysłowe.C...










Gorące części
- ISP817-XD
- XC6SLX100-2FGG676I
- GRM1885C1H220FA01J
- UCD9222RGZR
- EVK105CH0R8BW-F
- GCM32ER71C226ME19L
- UMK107SD332JA-T
- EPF10K30AFC256-3
- GRM2165C1H2R7CD01D
- GRM0225C1E5R7BA03L
- K5L2832ATM-BQ11
- SPNC801A-001A-PS031
- LTC1955IUH#TRPBF
- CL21B222KDCNFNC
- CL21B154KBFNNNE
- PS21A7A
- NTTS2P03R2
- MT45W2MW16BGB-708WT
- PTS645SK43SMTR92 LFS
- W39L010P-70
- 1206VC472JAT2A
- C0402X6S1A221M020BC
- GRT033C80J224ME01D
- SLG84516BTTR
- TMS320DM6446AZWTA
- FDS6681Z-NL
- AD623ARMZ-REEL
- HSMY-C150
- T197A206K010AS
- LM1086IS-1.8
- CY37128VP160-83AXC
- UPD78F1145AGB-GAH-AX
- PT2262-S
- LTC4252CIMS-2#PBF
- CC0805JRNPO0BN221
- NE592D8
- LM358APT
- T491X227K016ZT
- DS21552L
- S912ZVC19F0MLF
- CMM11T-121M-N
- CXA3562AR
- N80C186-25#
- TLV2264I
- IDT74FCT163374CPF
- BCM88060B0KFSBG
- C3216X5R0J107MT0A0N
- BG95M3LA-64-SGNS
- TPS54202DDC
- ALM2403QPWPRQ1